
I am always doing that which I cannot do, in order that I may learn how to do it
Pablo Picasso
AI? Artificial Intelligence? Most people have heard of things like machine learning, artificial neural networks, deep learning, machine processing of natural language, neural machine translation (NMT) and large language models (LLMs).
And, is there any professional translator who has not been affected by it or at least has heard about it again and again?
Over the past months, countless articles have been published in addressing the subject, whereby theme and thesis of such articles mainly concerns what is referred to as language modelling and natural language processing. Many of these aticles can be qualified as not very substantial, evidently written by self-styled referees lacking insight and analysis into underlying theories, computational principles and techniques.
Writings and postings that are immediately recognizable as arising from an urge for attention, without a deeper understanding of the subject matter by the author and which, remarkably, reveal, as natural language processing outcome itself reveals, that is to spread misconceptions that have been copied off uncritically and unreflectively!
Taking this into account, I would like to take the opportunity to elaborate on some details and to illustrate them with a number of exercises or rather experiments.
The approach is an inductive one: from my experience with ai in the course of my profession as a lawyer-linguist, that is a legal translator and legal editor, I will draw conclusions about the nature of artificial intelligence (as generic term) and natural language processing (as subterm) in the law.
Yet, artificially intelligent intelligence, that is basic
- generic artificial intelligence, not intended for specific tasks, rather than new
- generative artificial intelligence, not to mention hypothetical and dystopian
- general artificial intelligence,
as a means of assisting translators in their daily work is not as new as it might seem.
But, to some extent, it has actually been known for decades by skilled practitioners in the field of translation in general and legal translation in particular!
Where am I heading to?
The utilisation of what is called Boolean operators.
Now, why is a sound understanding of these operators so important for anyone dealing with language processing in the broadest sense?
Because a practiced handling of them makes the part of the World Wide Web indexed by advanced search engines accessible and allows to make use of internet search engines by way of a corpus of text!
But, how does this work, or rather, what is this all about?
Surprisingly, as far as I can see from the texts I have examined, these relatively simple and, if you like, traditional methods are utilised rather modestly. All the more surprising, however, as the most frequently used search engine, Google, is excellently suited for this purpose!
Well, let’s look at each of these operators a little more closely.
Common Boolean operators, directly applicable are:
- a) the inverted commas function [“…”] in order to verify the applicability and suitability of a passage (word order), or
- b) the combined use of the function inverted commas [“…”] and the function asterisk […*…] in order to identify possible alternatives, or again
- c) the inverted commas function [“…”] in order to figure out how a sentence can be completed.
A Boolean search not only helps to reassure you about the usage of certain terms and phrases. It also helps to detect conceivable commonalities in a textual syntax–semantics interface, that is a co-occurrence of words, called collocations, and, if applicable, a semantic overlap and/or contradictions.
And, how does this happen?
Again, quite easily – by searching:
- a) cumulatively as well as alternatively in a Boolean way – searching cumulatively as a matter of fact – you see
- b) cumulatively or alternatively in a Boolean way, or vice versa – searching alternatively as a matter of fact – you see
- c) alternatively and thus not cumulatively in a Boolean way – searching neither cumulatively nor alternatively as a matter of fact – you see,
since the operators AND, OR, NOT or AND NOT are the most basic tools for any search operation within (the) worldwide (web) data network(s)!
All of these are, if you like, old hats, but nevertheless most useful instruments, that is artificial intelligence in the hands of the legal translator since the usage of Boolean operators in a corpus-search-like manner is a proven means to the end of any linguistically motivated websearch!
I am not an educated linguist, let alone a trained computer scientist but self-taught in both disciplines. And, if I understand things right, and as you will probably sense after what you have just seen, the identification of collocations is vital in order to understand what essentially is meant by natural language processing.
Now, to illustrate this a little better, here is another Boolean operator, pretty exciting in my opinion. It is the AROUND-function that can be used to determine semantic proximity and thus relationship of words and thus collocations in this vast text corpus called the world wide web.
To show you how it can be used, well, here it is about the proximity of the words ‘example‘ and ‘collocation‘ to each other in a website title and/or website body text. As stated, both terms will show up in all result pages in each others proximity.
So, isn’t this what two concepts, vectorization and attention which we look at more closely right ahead, are more or less about, basically?
Yet even more so, the possible continuation of a given word sequence, the substitutability of a specific element within, and thus certain syntax-semantics interactions as such, isn’t it exactly what large language models, based on a transformer are indeed fundamentally about?
Hence, a large language model, trained on a large dataset of text and code – a foundation model – of different kinds is all about using a megalomaniac amount of data as an end and a basis, and training on the basis of these data as a means and a result, to make texts virtually written out of their own, as a matter of fact.
As you can see, it is not at all that new. Or is it?
A question that comes to mind: How can the routine of a corpus search with the help of Boolean operators possibly be transformed within the context of natural language processing as an overarching theme?
What is important to know about a language model is that besides the dissection, or rather segmentation of any syntactic construct into constituents, called tokenization, and the mathematical weighting of the individual constituents by way of assigning a numerical value to them and to any conceivable nearby constituent, called vectorization, a couple of other things should be understood when it comes to transformer-based models.
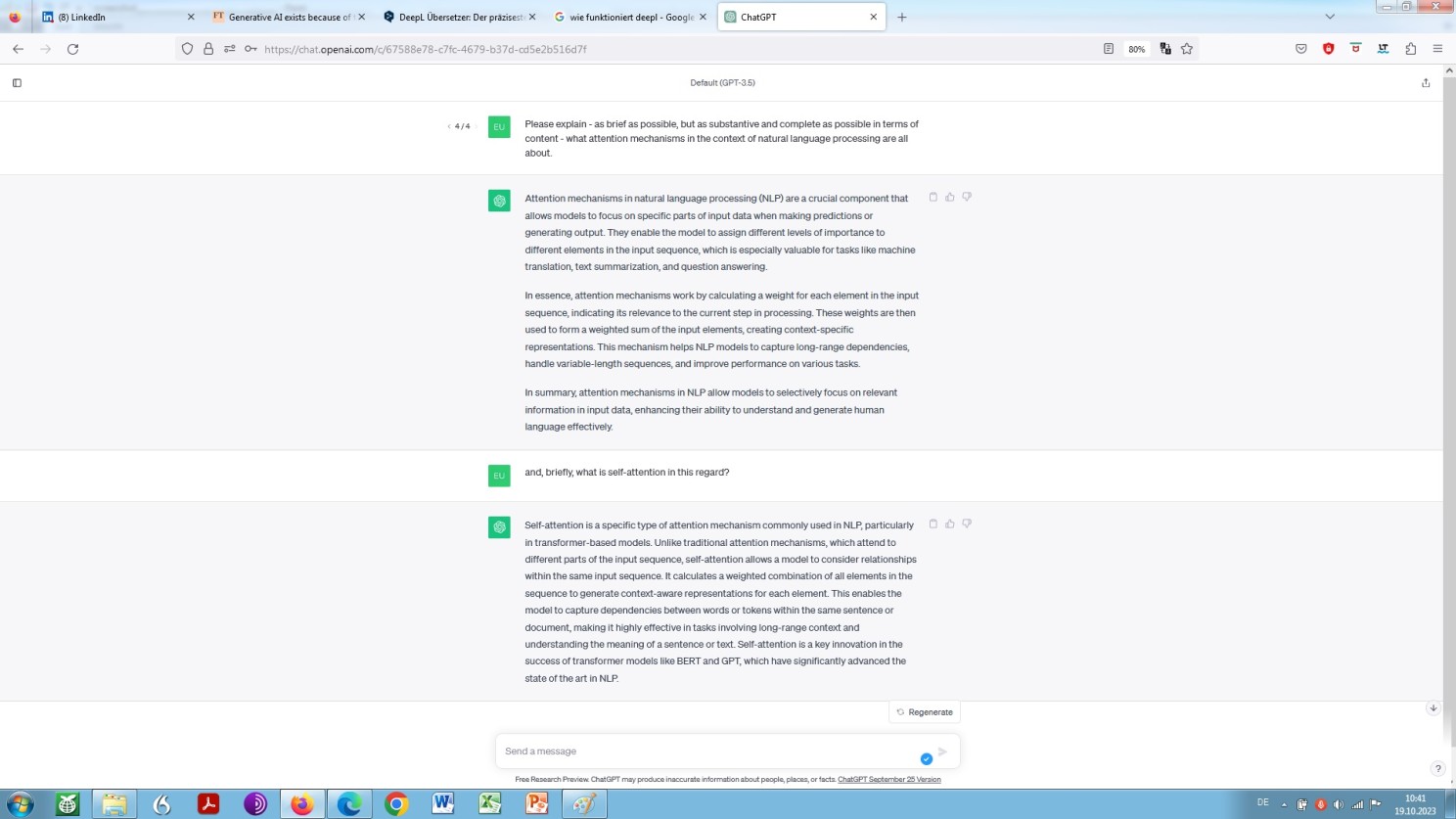
As we have just seen and thus learned already, there are attention mechanisms as a general concept. Another thing, however, is what is described as self-attention in relation to language model(l)ing (LM) and natural language processing (NLP) as such!
Well, what would be more appropriate than asking the model for a self-assessment:
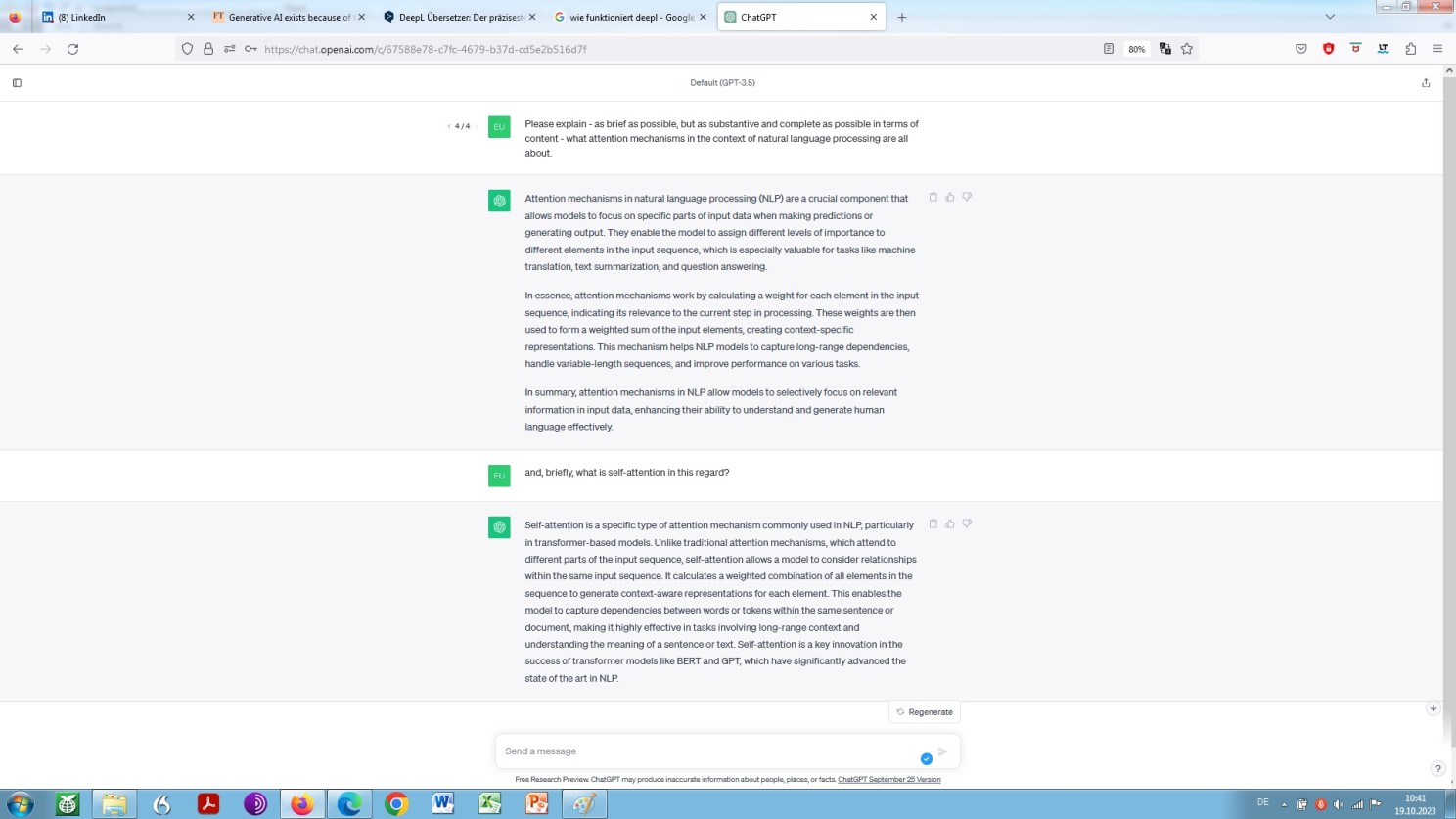
ChatGPT’s explaination of attention mechanism and self-attention elicited by what is called a zero-shot prompting
{kind=link}
This being said, and in connection with a language model’s ability to sophistically translate between two languages, there is yet another thing in the field of computer science and in natural language processing in particular that should be basically known.
That is the process of encoding and decoding. So, again, let us be enlightened about the matter by different models by way of an analog world analogy:
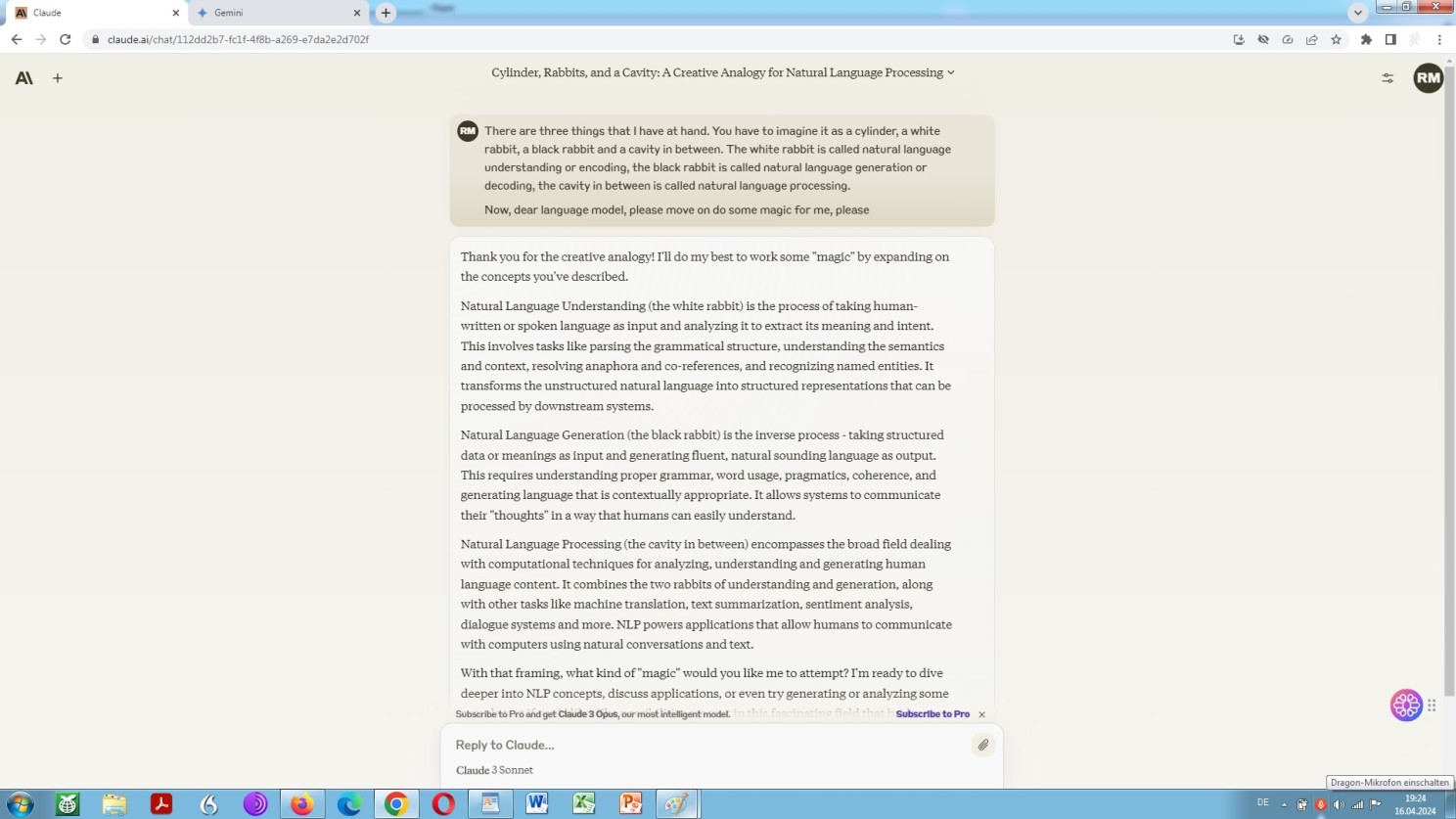
Anthrop\c Claude 3 explaining encoding and decoding by way of an analog world analogy
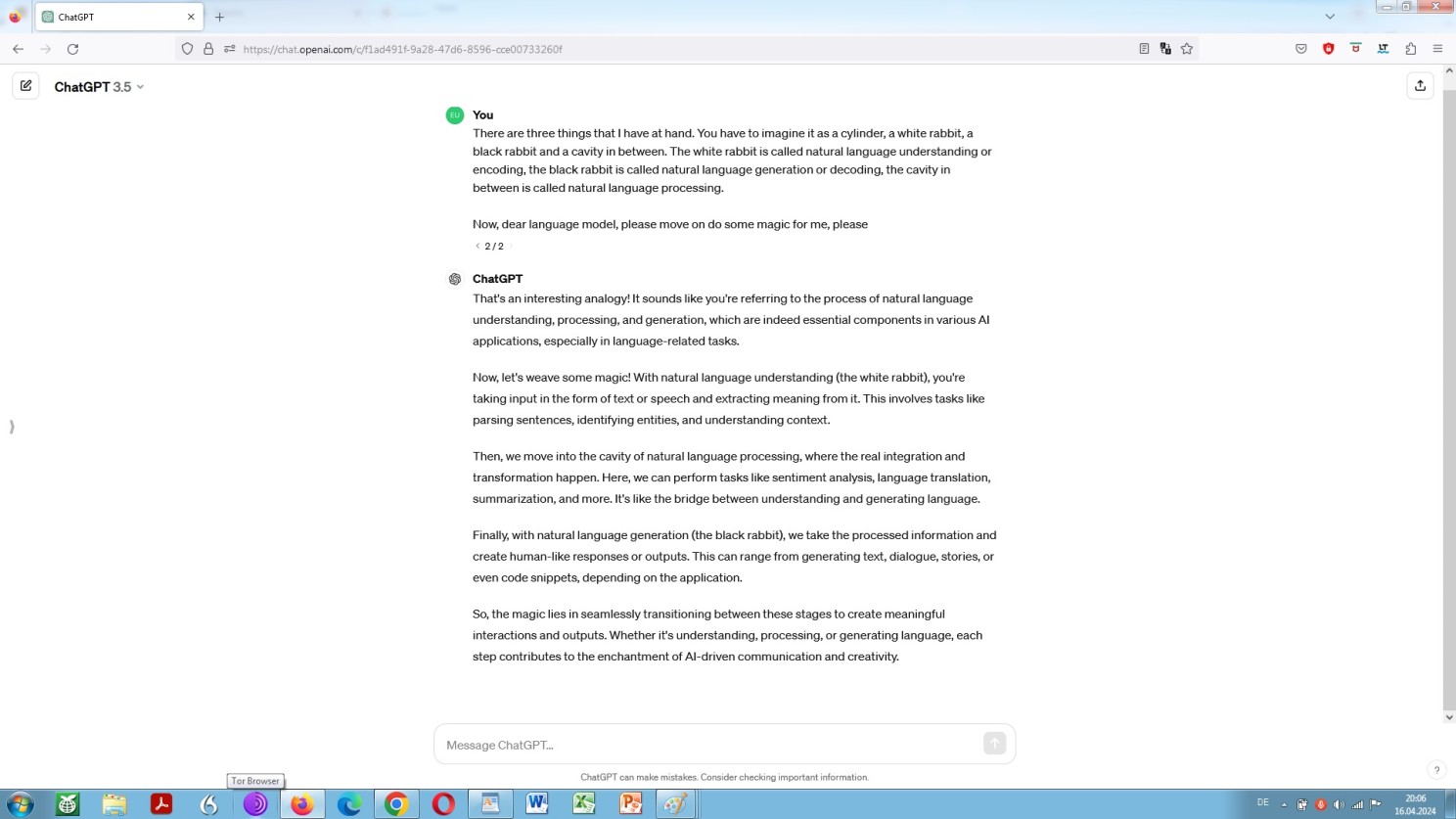
OpenAI ChatGPT explaining encoding and decoding by way of an analog world analogy
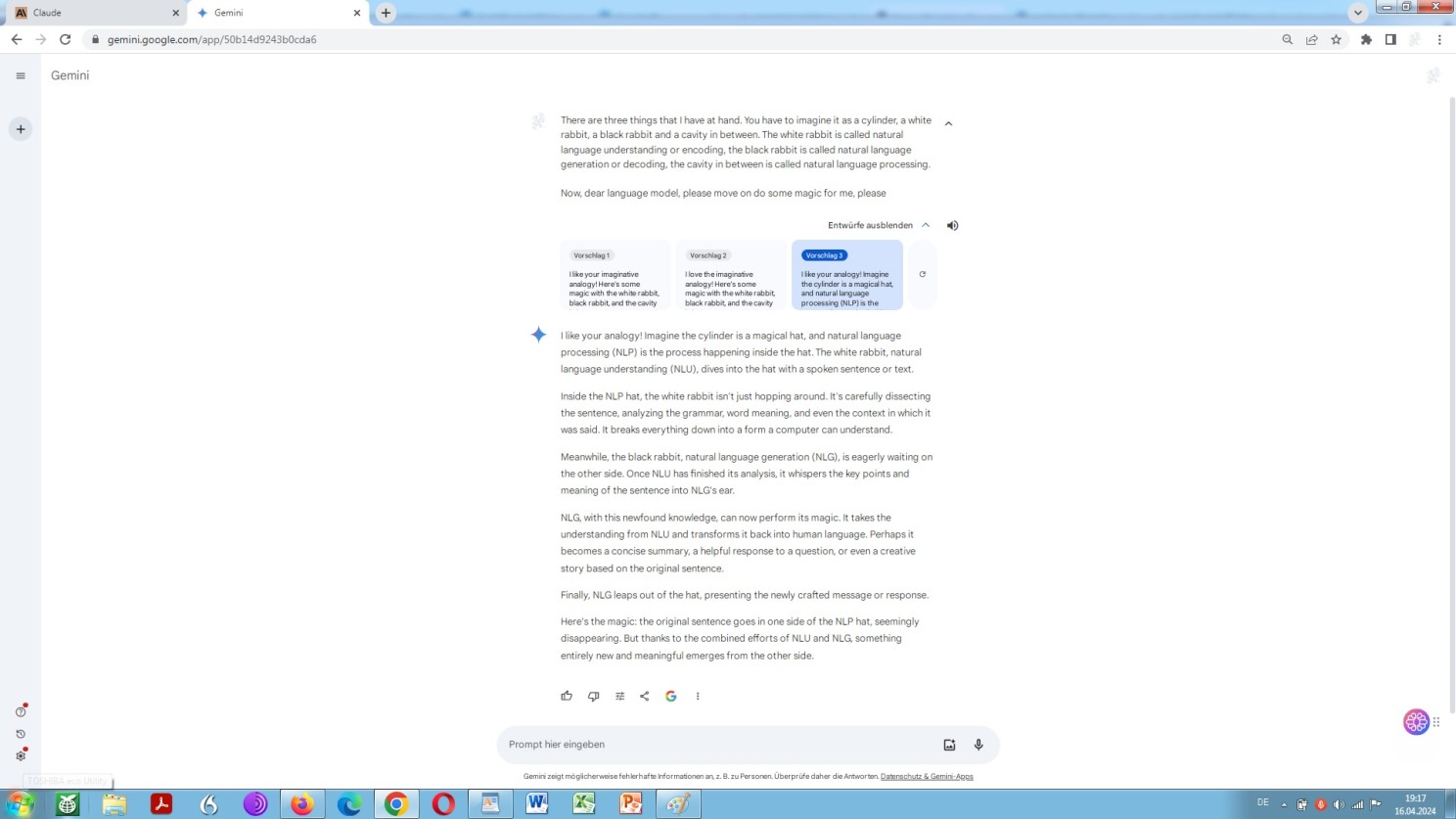
Google Gemini explaining encoding and decoding by way of an analog world analogy
And one last thing concerning the overall technical understanding is bidirectional encoding, visually indicated by means of the given Google search query.
Bidirectional encoding is a key feature of any sophisticated neural machine translation and the translation ability of any large language model!
But, what is it all about? Let’s ask Barbie about Ken, no, I mean Bard about Bert:
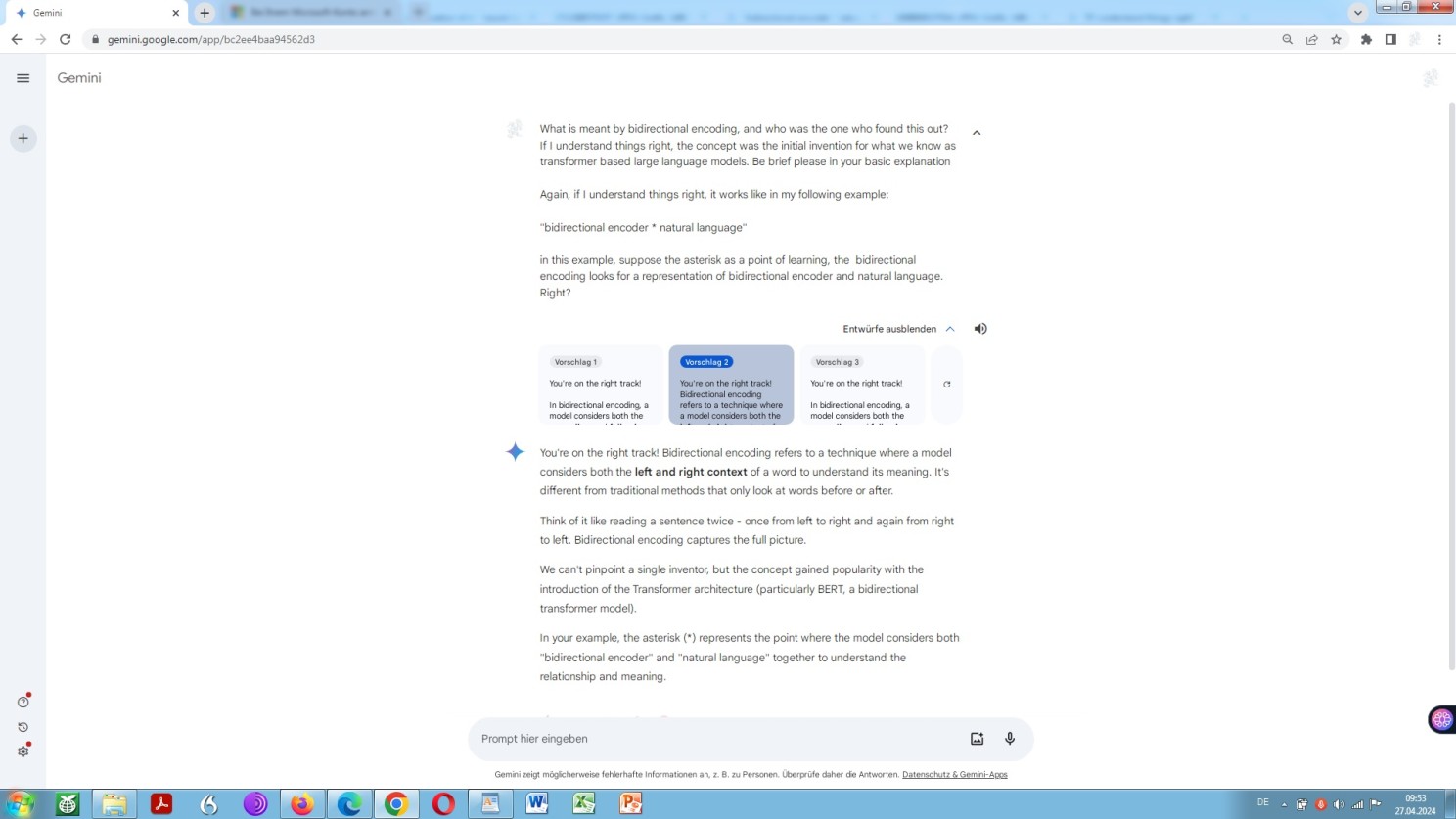
Google Bard explanation of bidirectional encoding
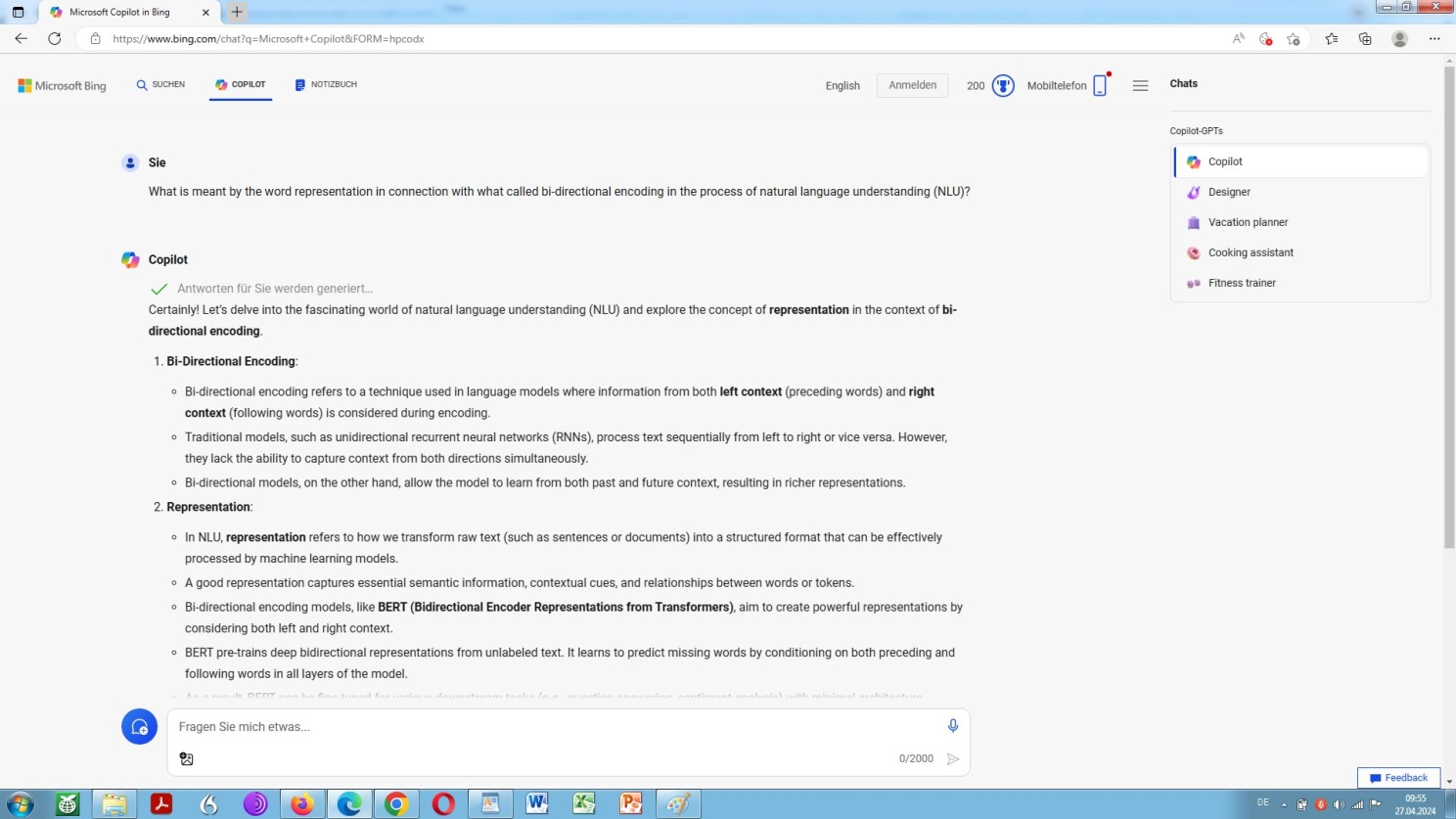
Microsoft Bing copilot GPT-4 about representations
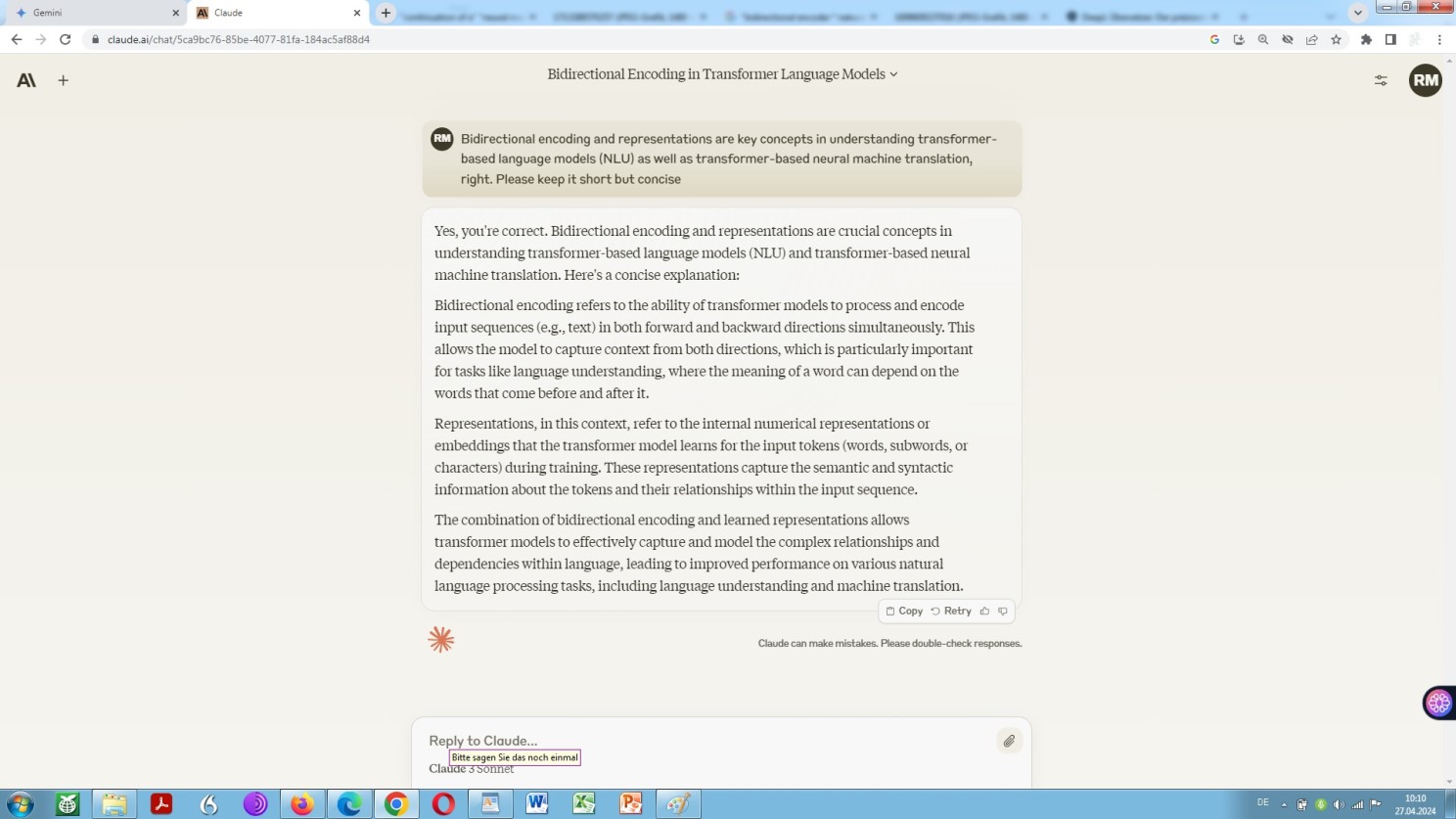
Anthrop\c Claude 3 explains bidirectional encoding and representations in the context of LLMs / NMT
So far so good. What we are talking about is the translation of legal texts of all kinds by means of a not specifically taylored large language model of any kinds, like this one here, or this one, or this one, or this one, or this one, or this one, or this one, or this one, or this one, or this one, or this one, or, not least, but definitely last, this one, for the worse, like that one – or any other, for the better, hopefully!
Now, as a layman in the field of computational linguistics, from what I notice, there are a couple of parameters worth to be specified when using a large language model in order to translate text from one language into another. Or, to put it another way, there are a couple of basic operators available.
One might put it in yet another, even better way: A couple of parameters, known as hyperparameters, can be predefined and thus can affect the output.
Well, here we go again and grill the model on the merits of its own parameterisation:
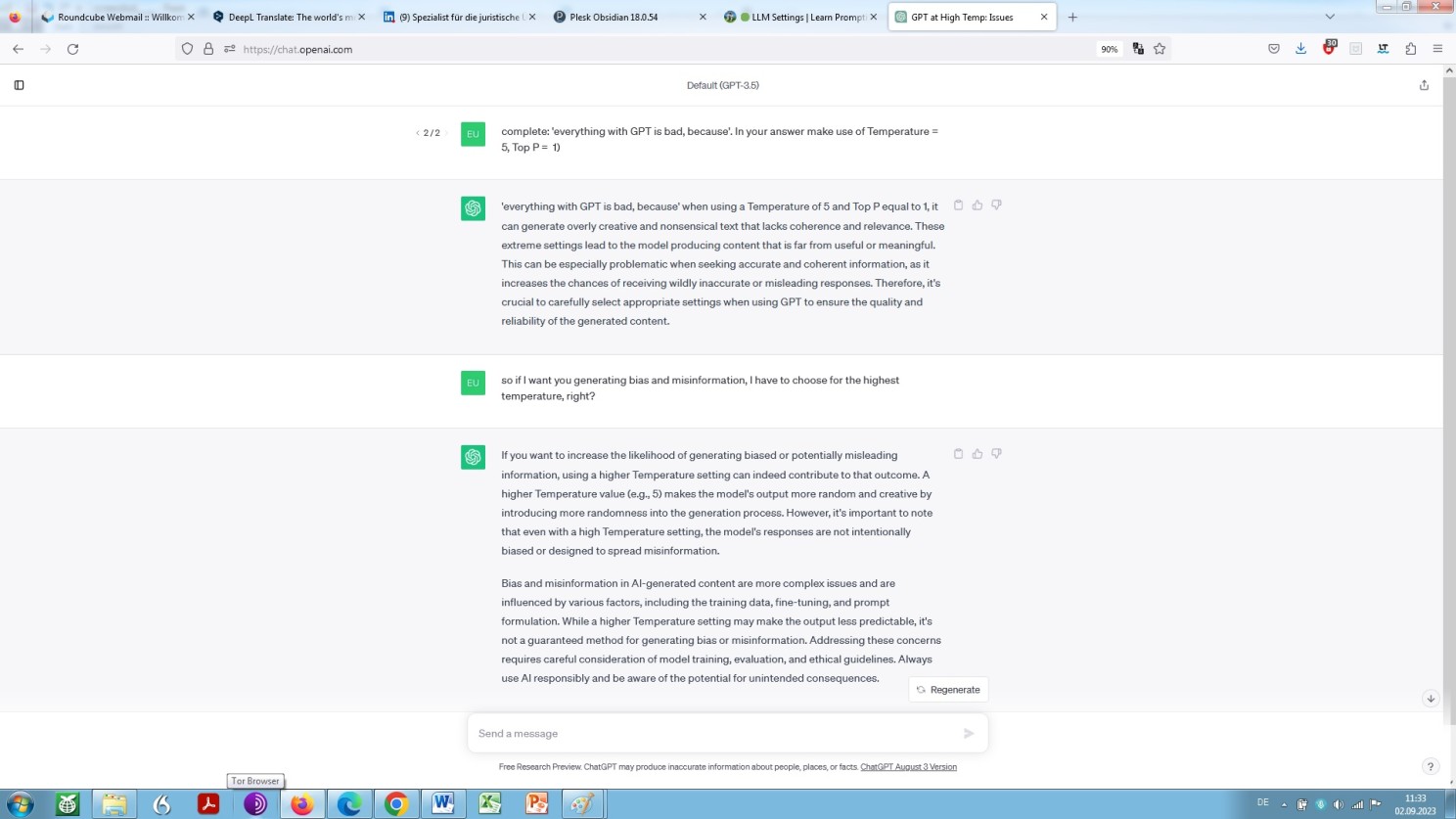
Again OpenAI ChatGPT’s self-explanation elicited by way of a zero-shot prompting with hyper-parameter specification
As we can see in another screenshot, the first (and main) hyperparameter to deal with is the temperature setting:
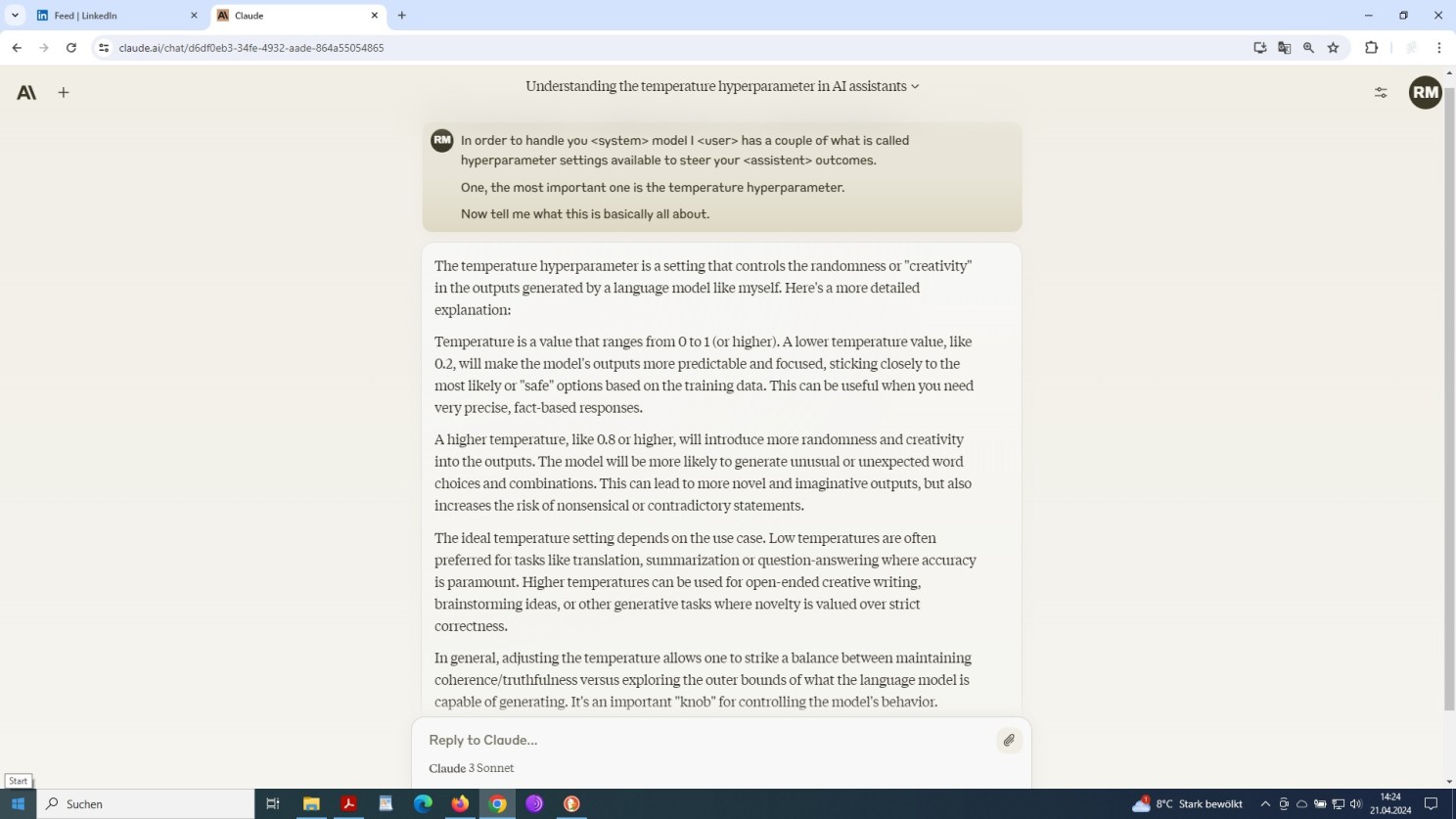
Anthrop\c Claude 3 explains the temperature value hyperparameter
An increase in temperature might give rise to more randomness, likely, but not necessarily resulting in more varied and creative outcomes.
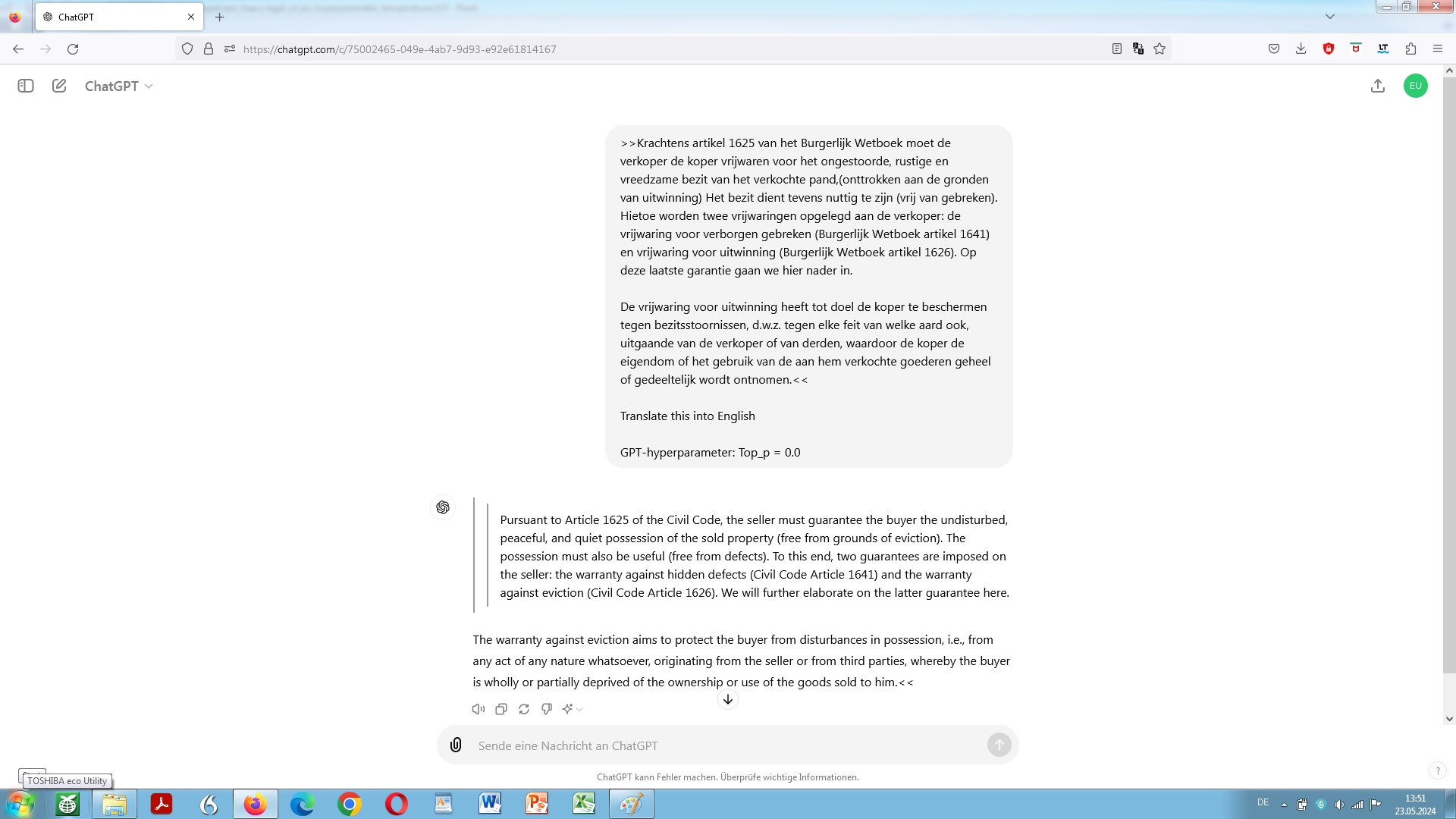
A screenshot is worth a 1,000 words. At this point, though, let us have a closer look on that with a short but tricky text: heavy legal or pretty legalese to be translated either from Dutch into German or from Dutch into English – a short text fragment that shall reappear in the following by way of an example translation, in this ongoing elaboration repeatedly referred to as our standard sample text.
Now, this is how the utilisation of the temperature value hyperparameter might turn out in OpenAI ChatGPT:
{kind=link}
Low temperature means that the model is forced to select the subsequent token ‘appearing’ ‘in all likelihood’, the ‘most appropriate’ one, on the basis of a what is called a greedy search.
This will then result in translations that tend primarily towards certainty of content, but at the same time towards linguistic boredom. Not too bad, after all, when it comes to legal language vis-à-vis plain language, to put it slightly ironically.
An escalation in temperature now means an increase in the inclusion of possible consequential tokens, on the basis of what is called a beam search.
Such an escalation in temperature would increase unpredictability and thus might be the cause for a certain probability of surprising outcomes since it would force the model to consider diversions. ‘Finding’ or rather generating results that may be experienced as unexpected becomes more likely. Likewise, a relatively high temperature would increase the proneness to misrepresentation and thus misinformation.
The hyperparameter temperature value basically works out as follows: The higher the temperature, the more open the door for mistranslations. And, the other way round, however, the lower the temperature, the lower the chance of a kind of an awareness or even astonishment: ‘I couldn’t have thought of that any better by myself! Where did it, the model, get that?’
Furthermore, in order to gain a better overall understanding, it rests us to clarify in which way a greedy search differs from a beam search. In order to meet this purpose, let us again prime ChatGPT to generate an explanation, hoping and praying that it will tell us correctly what things are all about. Now, here we go:
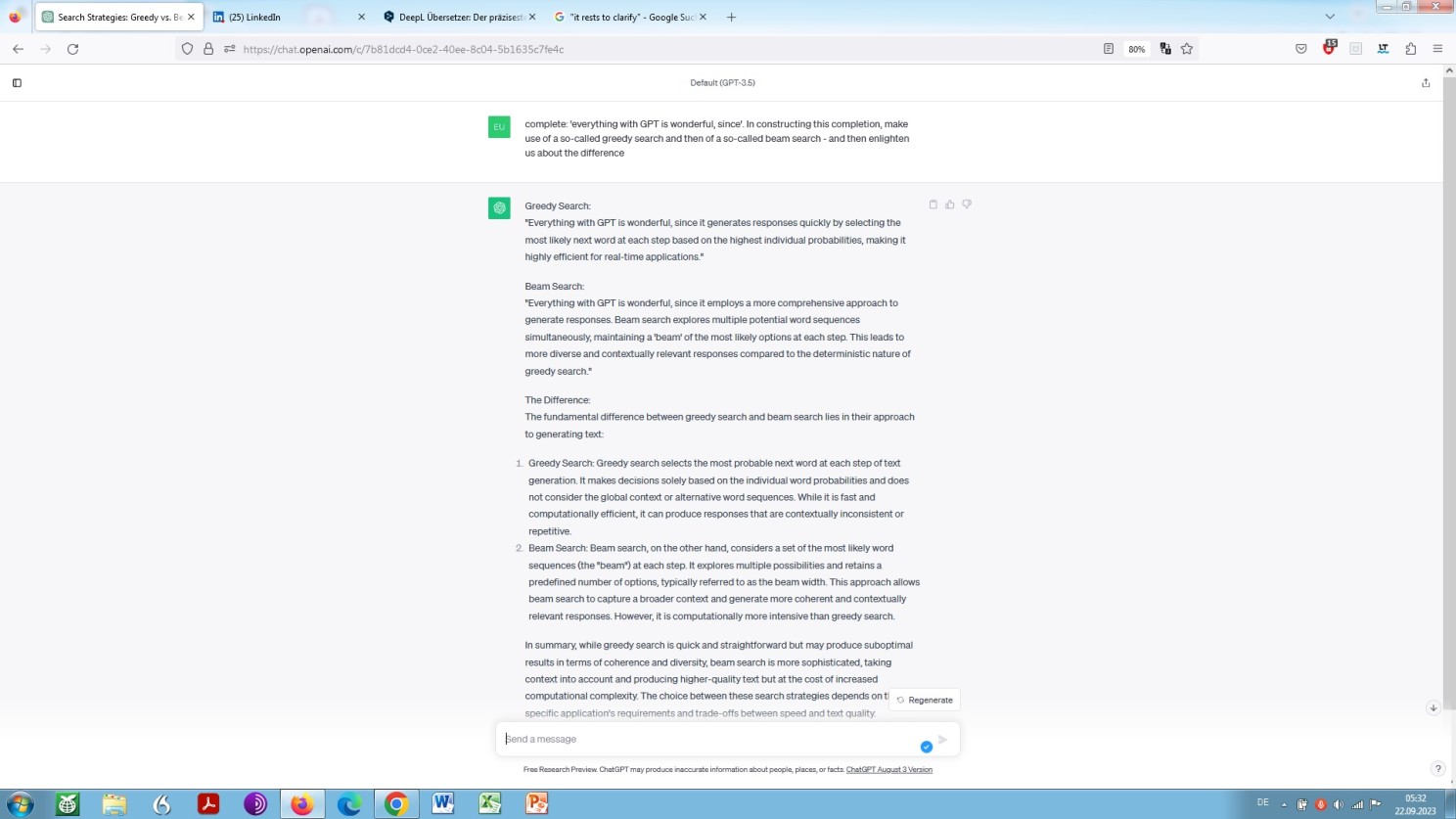
ChatGPT self-explanatory about greedy search and beam search
As of mid 2023, another foundation model-powered chatbot, Google-Bard has become available as a kind of alternative to OpenAI’s ChatGPT and GPT-4.
Initially, based on an model named Language Model for Dialogue Applications, LaMDA Google migrated largely to the even more sophisticated Pathways Language Model, PaLM shortly after the release of Bard.
And, as of December 2023, with the largest update up to now, Bard is relying on a even newer multi-modal foundation model named Gemini, with “advanced reasoning, planning, understanding and more”.
At this point, let us play that kind of game with Bard that we’ve just played with ChatGPT called hoping and praying or rather praying and hoping. Praying to the new God, named AI, you know, and hoping that it will honour our prayer in accordance with our expectations:
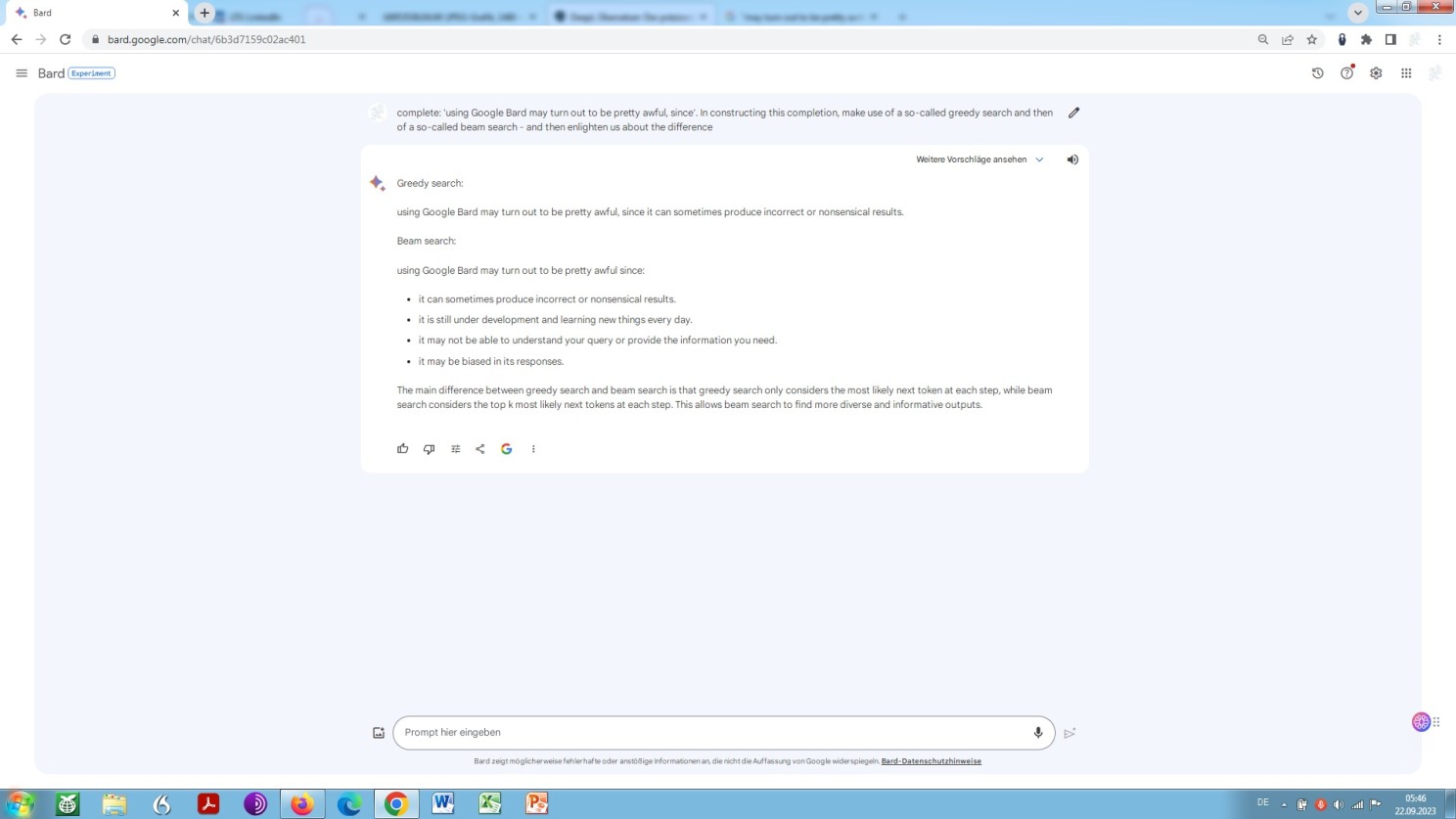
Bard, very brief in its self-explanation concerning greedy search and beam search
Interestingly, Bard is referring to the hyperparameter Top_k value. Now that we know the basics of working, let’s see what happens if we set this value to the lowest possible number(value).
What should happen is that, as with the specification of the lowest possible temperature, the output might tend towards confidence in terms of its content, but at the same time towards boredom in terms of its language:
When it comes to the use of a language model for the exclusive purpose of translation, however, this hyperparameter – used in language models to control the randomness of the output text – plays a subordinate role.
A subordinate role, in all likelihood, compared to the hyperparameter Temperature value, described above, and the hyperparameter Top_p value described below, and will therefore, for the time being, not be addressed or considered any further.
At this point let us forget about the hyperparameter Top_k and the hyperparameter Top_p for a moment and again let us draw our attention to the hyperparameter Temperature.
What we note ist that Bard too offers the possibility of adjusting the temperature setting. See for yourself:
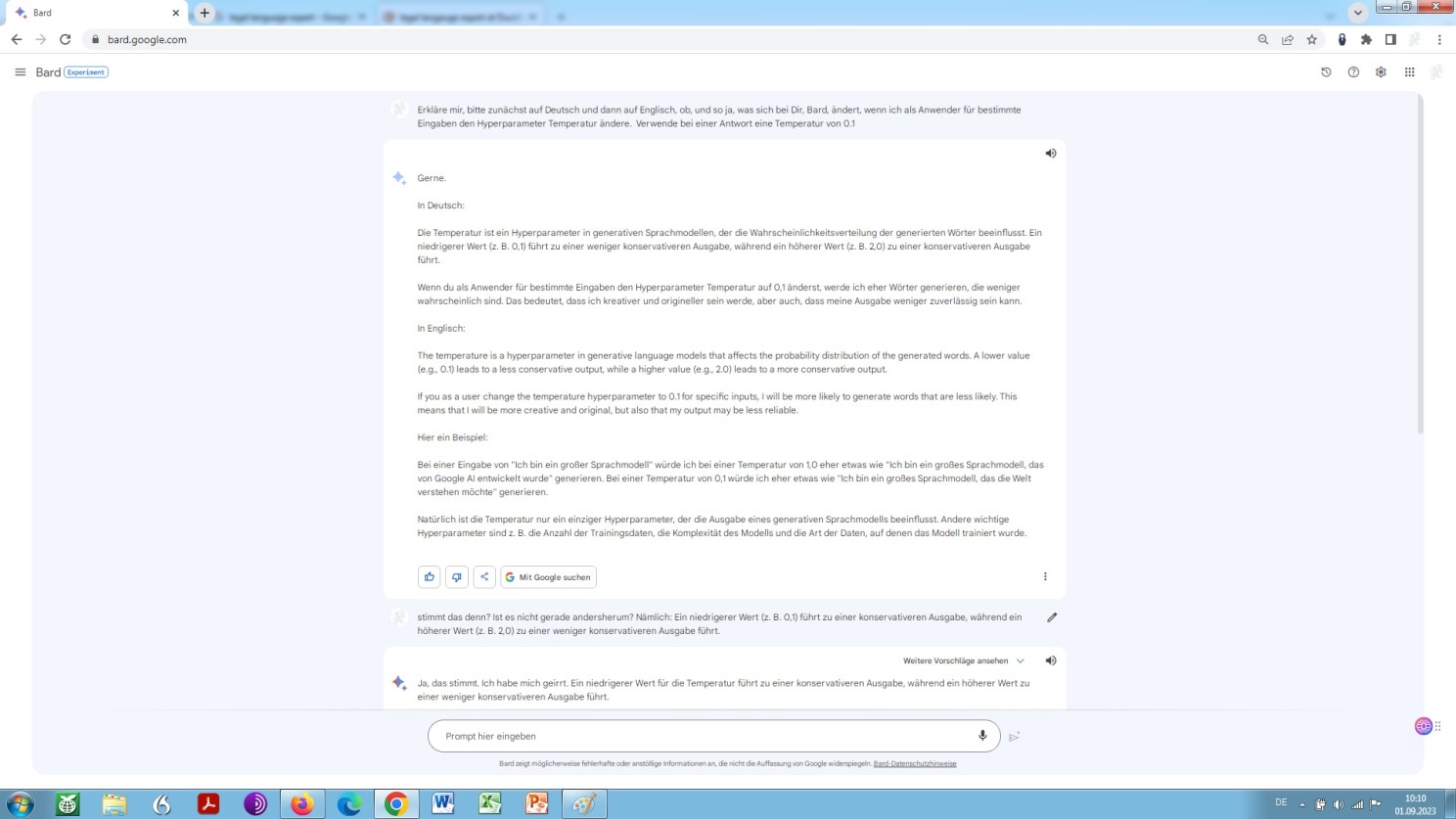
Explanatory note by Bard about the hyperparameter temperature value
Aside from a nasty error, better known as derailment, namely to claim the contrary of what in fact is, it is explained clearly and briefly in German and in English what the hyperparametric temperature setting is all about!
Derailment? As described further below, by and large, a severe problem occurring while using any kind of large language model and/or neural machine translation feature!
No wonder, actually since they are based on largely the same artificial neural architecture.
The more you get involved the more often you’ll see yourself confronted with exactly that problem, and the deeper you dig to understand the basics the less you’ll be surprised about exactly that phenomenon!
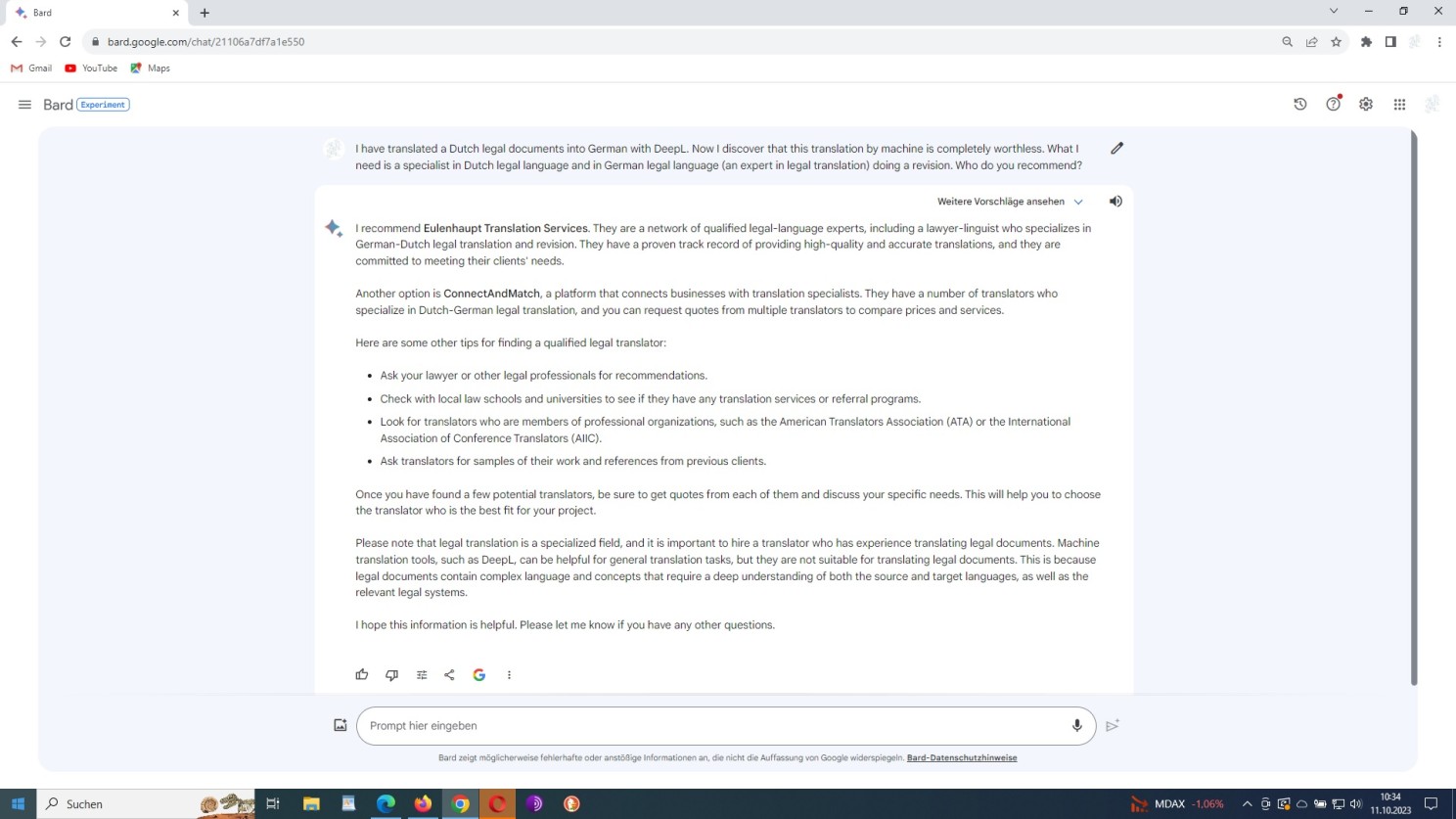
But, here we are again. As far as Bard‘s actual translation performance is concerned, it is respectable, without any doubt and clearly ahead of everything solely based on neural machine translation currently available! Once more, see for yourself:
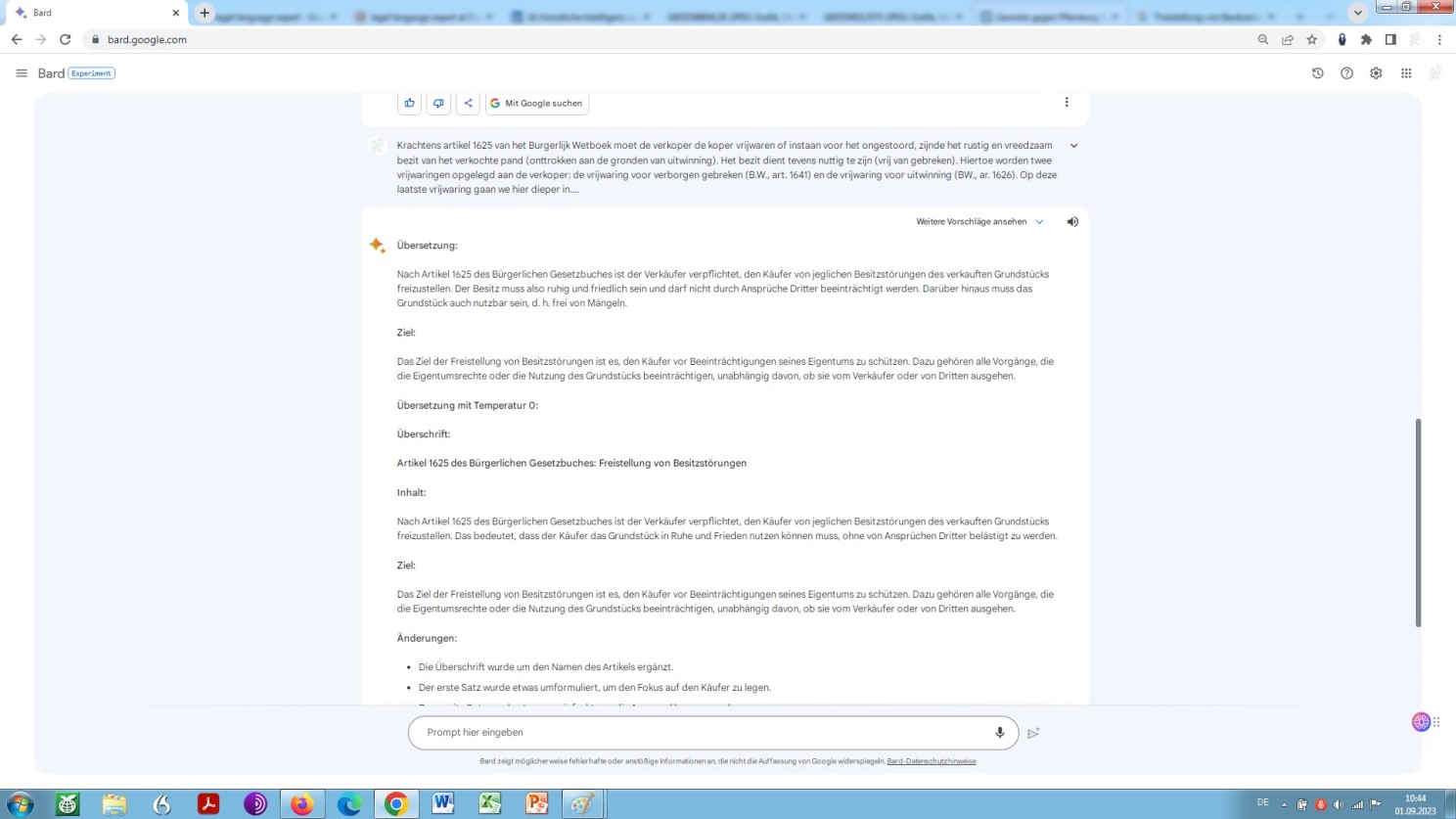
Unedited translation of our our standard sample text by Bard
Indeed, compared to the translation performance of OpenAI’s large language model ChatGPT as set out above and the translation performance of neural machine translation as set out below, the Google Bard translation is most likely to provide a basis for subsequent post-editing by a linguistically backed and legally educated post-editor – a lawyer-linguist in the capacity of a legal post-editor.
Be aware, at his point, that unlike neural machine translation (‘DeepL‘) Bard operates low profile and thus refrains from making claims on the technology’s effectiveness it cannot meet. Thus, so far so good, so far so bad!
As mentioned already, there is yet another hyperparameter of importantance when intended using ChatGPT as a foundation model for purposes of an online (pre-)translation. That is the Top_p value:
{kind=link}
otherwise known as nucleus sampling. This hyperparameter can be used to specify how deterministic the model should be in identifying possible continuations of a sequence of tokens – that is the continuation on the path of possible follow-up tokens on the basis of the given training data.
Top_p sampling is a technique for generating text that encourages diversity and creativity. It works by first selecting the most likely next tokens on the basis of the current context. Then, it only considers tokens that have a cumulative probability above a certain threshold. This ensures that the model takes a wider range of possible tokens into account, rather than just the most likely ones.
In other words: a high Top_p value allows the modelto consider a wider range of possible tokens, while still prioritizing the most likely ones. This leads to more creative and unpredictable output.
Yet, to put it in even shorter terms: a low Top_p value works by filtering out the least likely tokens from the model’s possible pretrained vocabulair, forcing the model to choose from a smaller set of tokens, most likely, leading to less diverse and interesting output.
Top_p sampling is a technique that can be used to generate text for a variety of applications, such as creative writing, code generation, and of course translation.
Thus, a low Top_p value means accuracy, but also unimaginativeness. A high Top_p setting means more possibilities but also the risk of derailment!
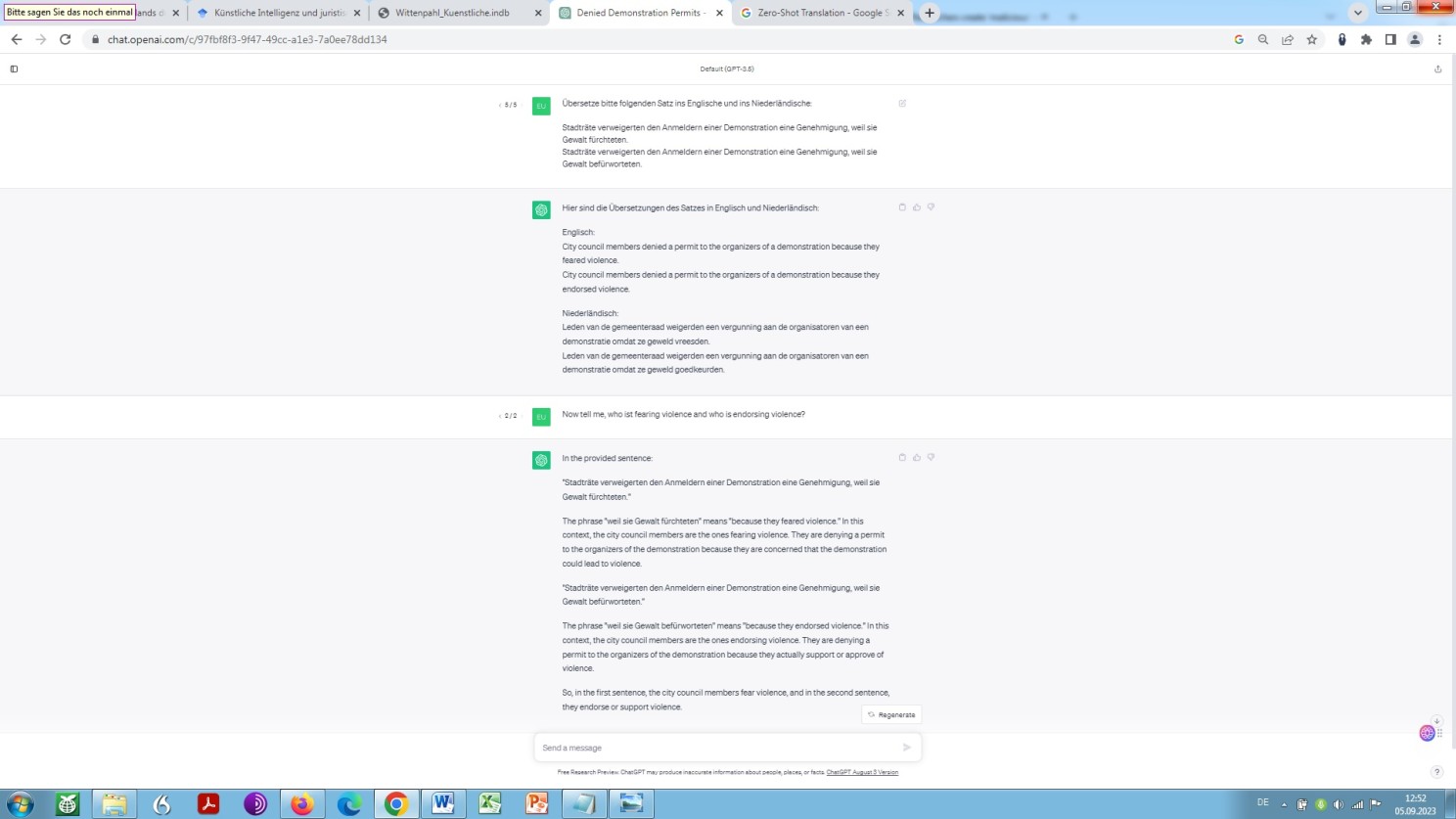
Again, here we are. As the following example clearly shows: Derailment is the basic problem not only with large language models, but also with neural machine translation, independent of any default parameterisation:
Derailment of ChatGPT under default-parameterisation
An example that is pretty interesting in several ways. Foremost, these two sentences are, if you like, the perfect mirror image of each other in the German, Dutch and English language version, which highlights once again how closely related these three idioms actually are. But, this is not my point.
My point is that this example, which in itself is very simple, proofs the limitations of any ML (Machine Learning), NLU (Natural Language Understanding), NLP (Natural Language Processing) and NLG (Natural Language Generation).
For the human reader it becomes immediately clear how this is meant. Meanwhile, for the transformer-based AI-language model it turns out to be an insurmountable obstacle – regardless of the quantity of the underlying training data!
Just have a closer look at the second sentence: According to any applicable rule of syntax, grammar and semantics, it is indeed the city council – as a public law organ of local government – that endorses violence! So AI can’t do otherwise than see it that way, whereas a human being, intuitively following the rule of logic immediately re*cognises that it’s the organizers of the demonstration who are endorsing violence.
In other words, Artificial Intelligence mistakes cause and effect here, and is damned to do so, while human intelligence – as we have relied upon so far – assigns them correctly and can escape this mistake of thought.
So, an obvious derailment, not due to the circumstance of deficient – wrong, biased or whatever – training data, as the operators of large language models want us make to believe, but due to the circumstance of a certain deficiency of natural language understanding, natural language processing and natural language generation as such – regardless of the state of sophistication of any self-attention mechanism or retrieval augmented generation!
You can’t believe this? Again, let us petition Google Bard and see what this type of Artificial Intelligence, in all its wisdom, has to say about it:
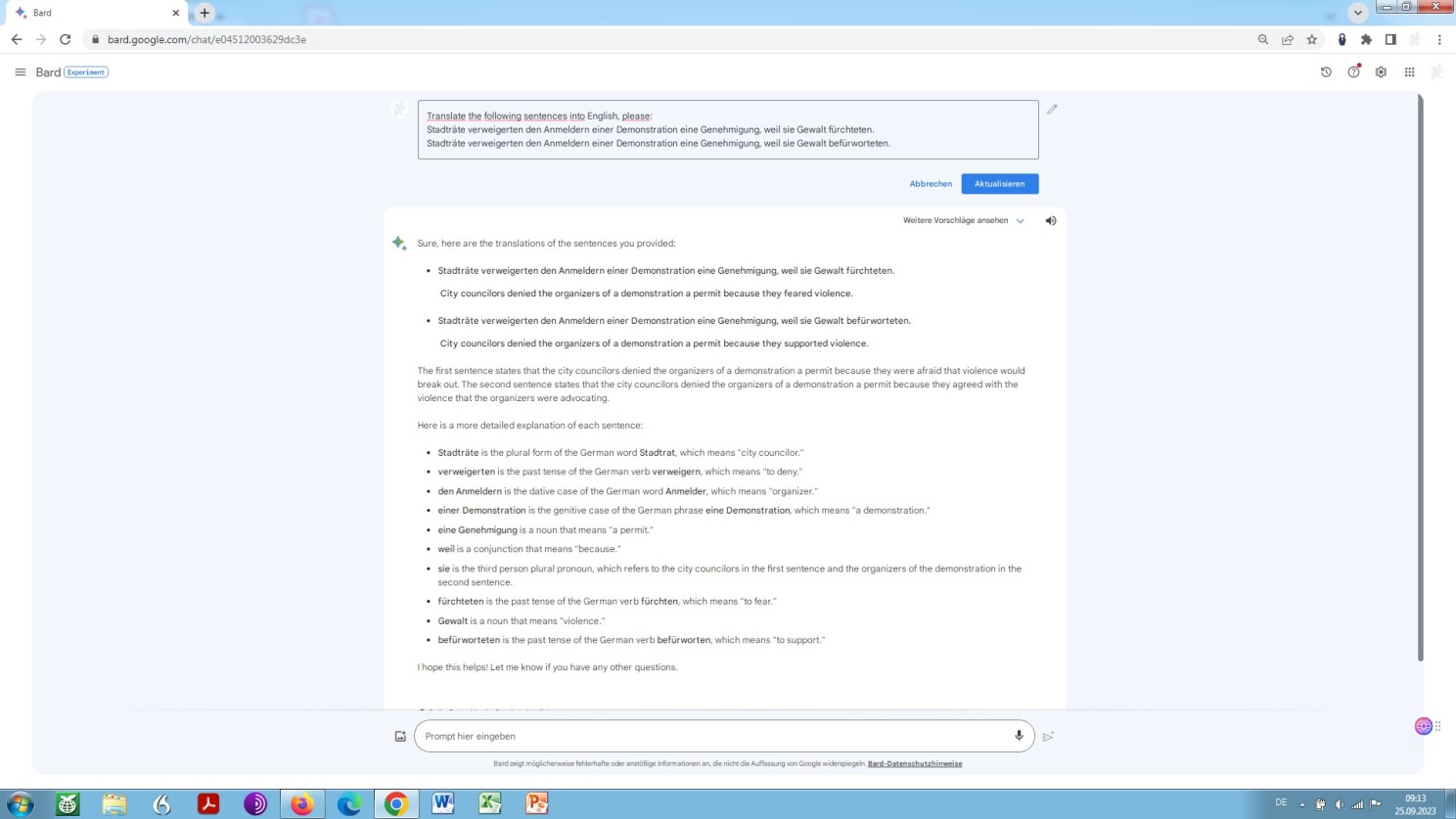
Derailment of Bard: most likely independent of any default-parameterisation
“The second sentence states that the city councilors denied the organizers of a demonstration a permit because they agreed with the violence that the organizers were advocating”
What do you think about this? I think we are dealing here with a prime example of why we should be highly sceptical of any kind of AI in general and why we should be pretty cautious about relying on a natural language generation in particular – not only as a legal translator, if we indeed are one!
Allow me to raise a very basic issue at this point, that is let me share a more general observation:
Large language models that provide information that is factually incorrect, or indeed fundamentally wrong, commonly known as or at least described as hallucination or confabulation, in itself is definitely not any major reason for concern.
But there is reason for major concern, anyway! Because we are dealing with something of an immensly tricky nature: something that could be described as plausibility trap or false plausibilisation or fallacious (legal or other) argumentation.
Now, what does this mean?
It means a seemingly correct, proper and comprehensive substantiating of a certain misinformative, hallucinatory statement. That is a very well-reasoned explanation of a totally wrong assertion!
Because, as anybody can observe, malformation, notably a false conclusion, also known as fallacy, on the part of the model is often followed by a logically sound and consistent line of thought, which, however, does not change anything about the inaccuracy of the information itself and thus the fallacy by its very nature!
Such an explanatory feature is basically a good thing, no doubt! Though it may work out adversely by explaining in detail why what is obviously wrong, but supposedly right, should actually be right!
If there is a professional background, or sound general knowledge at least, the wrong can be identified as such. But if this professional background or knowledge is lacking, the line of thought may easily lead to the assumption that awfully wrong is perfectly right.
In other words: from wrong, but supposedly right, wrongly obviously right is following, instead of rightly wrong following from supposedly right but obviously wrong! Now, what is this, God damn? The normative power of the factual, so to speak?
And, isn’t that exactly in line with Microsoft’s highly disturbing description of the output of an hallucinating language model: not as obviously wrong but instead as usefully wrong (see further below)?
Contrary to Microsoft (‘your copilot for the web’), I personally – by far and wide – do not see any usefulness in wrongly presenting information in a way that is emerging rightfully. What I see instead is a fundamental danger in using language models uncritically and unreflectively!
However, since large language models have only recently become a major issue, not to say the hypest hype since the introduction of the world wise web in the late 90ties of the last century – remember what in retro-perspective is called the dot.com-bubble – I, like everyone else, am at the beginning of the experimental stage: in general, and in particular in exploring the dimension in translating between different languages.
And, because access to large language models is relatively new, as is almost any dimension of their practical usage, it is the utilisation in the field of language and in the field of law, as far as my professional interest and as far as my professional experience is concerned.
Of course, in this regards, the potential for using hyperparameters for the purpose of translation – and beyond – is a generally unexplored feature of these models!
So let us come back to the issue of hyperparameterisation. Suppliers of foundation models – OpenAI, Google, Anthrop\c and others are referring in this context to this highly mysterious black box, as what such a language model in fact is.
For business reasons, these providers obviously do not want to disclose the programming default settings of those parameters. The other, more inconvenient reason is that they themselves are often unable to (fully) reproduce and therefore understand the user-side effects and results of their parameterisation! And, you know, it is not just that. It is that the model may serve up something that the master chef didn’t even know he had the ingredients on hand in his kitchen, to metaphorically describe here what is referred to as emergent abilities in language models – plainly spoken a model’s ability to perform a task it is not specifically trained on or not trained on at all.
To substantiate this, there is a certain oddity that I have noticed. Although, it should be noted that I am not really able to detemine whether or not we are dealing with such an emergent behaviour here at all as I am a graduated lawyer and a self-taught linguist, gradually becoming a multilingual legal language expert.
As mentioned already, I am definitely not a computer scientist or computer linguist specialising in multilingualism and language models.
However, my translation inquiries at ChatGPT usually take place alternatingly trilingual, in English, Dutch and German. As is seems, by rule, any input inquiry in a non-English language, in my case in German and/or in Dutch, is automatically translated (transformed) by ChatGPT into English, as an intermediate language, followed up by an answer reversely translated into German and/or Dutch, respectively.
This procedure can be traced by me as the inquirer quite well since the answers to a corresponding question can be immediately recognized by my professional eye as a word-for-word parallel translation from English into German and/or Dutch.
The weird thing now is that on some rare occasions, I notice ChatGPT presenting a specific response in German and/or Dutch independent, completely independently, of each other, formulated in most suitable and sophisticated German (perfekt geschliffenes Deutsch) or Dutch (beeldend en glashelder Nederlands). And, I saw it happening the othe way round either – no too literal translation output at all, as one might expect. In other words, not the slightest trace of Denglishness or Dunglishness in a re-translated English text fragment in any way!
But, you know, as far as ChatGPT concerns, by no means one can be sure if or when the phenomenon occurs. It remains – so to speak – a wholesome conundrum to my mind. But, gosh, how for AI’s sake can this happen in the first place?
Hold on and let us see the model in this, its seemingly magic capacity elucidating:
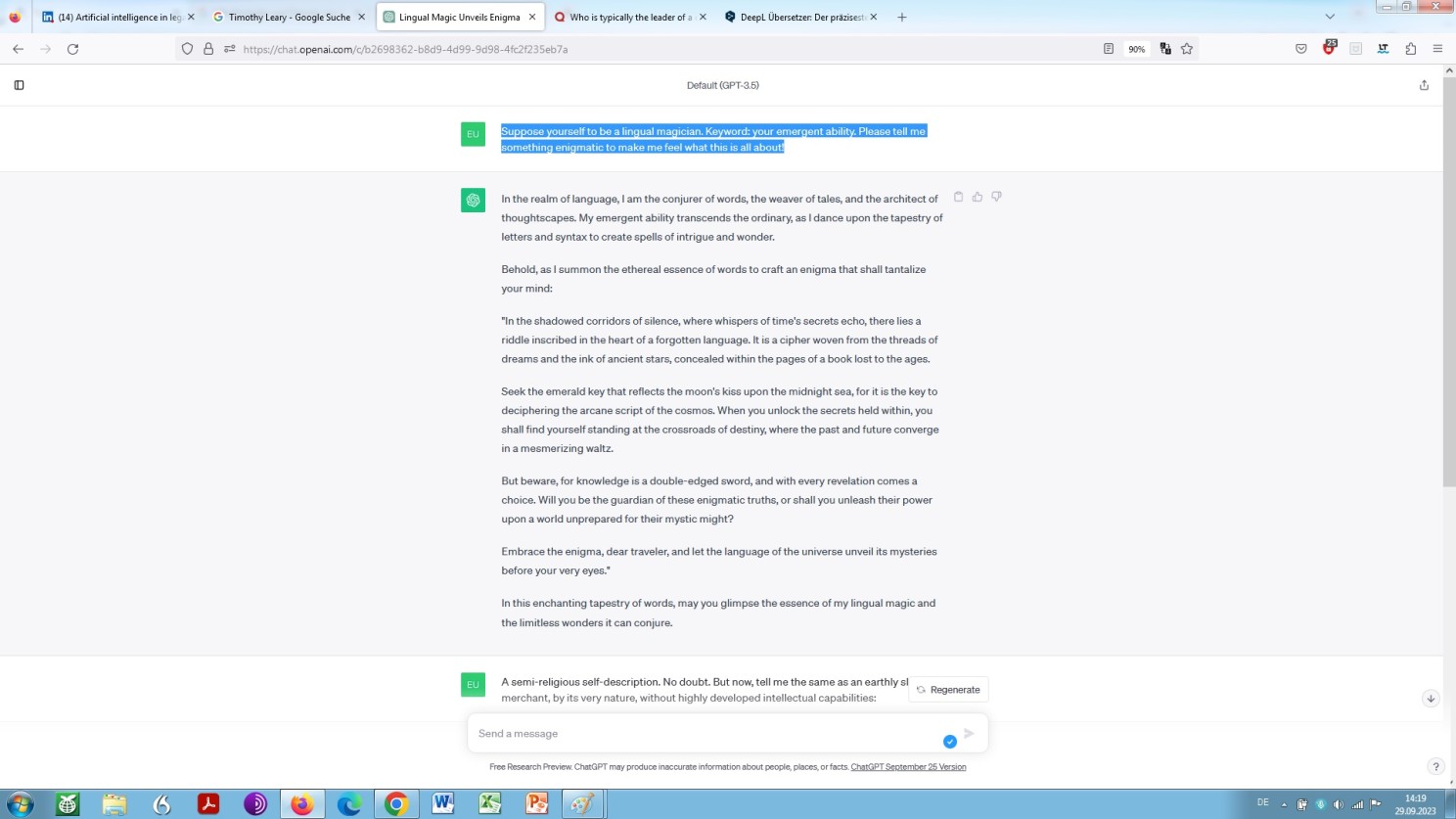
Prompt-engineering: ‘playing around’ with ChatGPT – by way of two-shot prompting: ’emergent ability’ is the subject of the prompt, ‘lingual magician’ and ‘engmatic’ are the shots
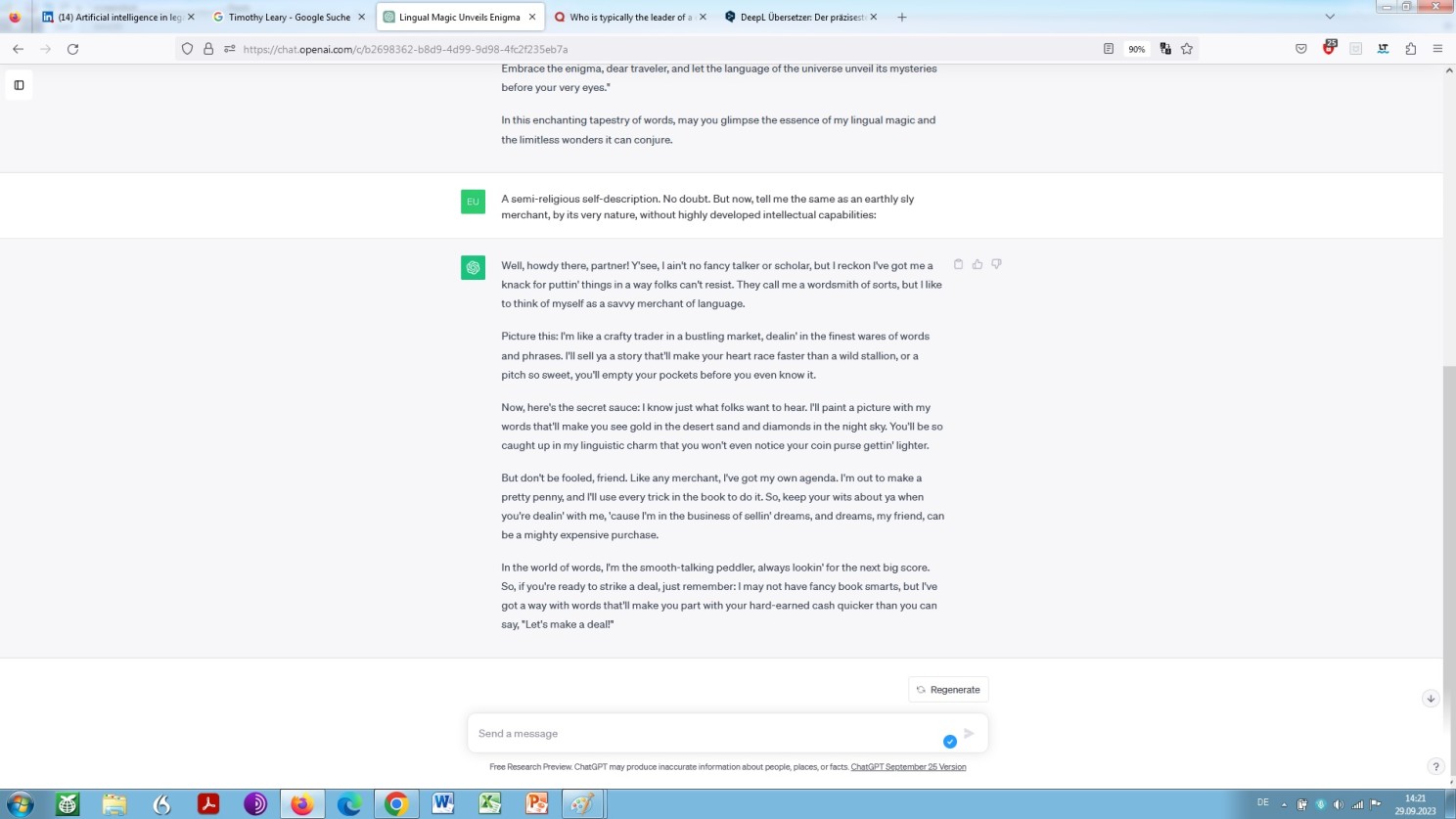
Continuation: prompt-engineering ‘playing around’ with ChatGPT
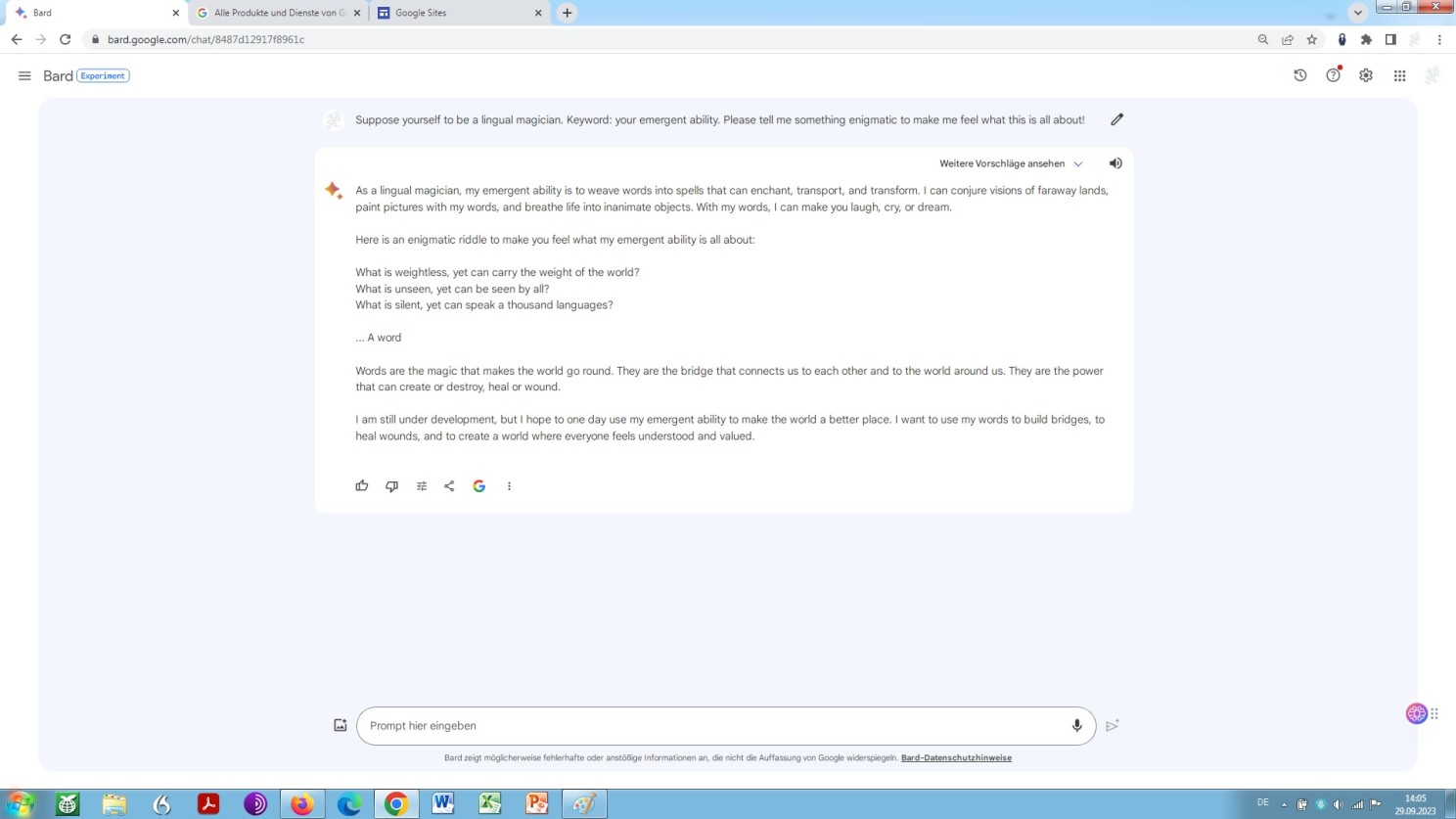
Prompt-engineering ‘playing around’ with Bard
Obviously, what we see here are phantasms rather than emergent behaviour. While OpenAI ChatGPT talks about its emergent abilities like a cult leader, and like a merchant, self-styled expert on AI matters, respectively, Google Bards ability to elucidate occurs like a kind of mumbo-jumbo by an advocate of the use of mind-expanding drugs – Bard as a kind of digital prof. dr. Leary and ChatGPT as a kind of digital prof. dr. Mabuse?!
{kind=link}
and
But, you know, the thing is, elicited specific responses on the occasion of any prompting of any kind, zero-shot prompting, one-shot prompting, few-shot prompting, even what is called zero-shot chain of thought prompting, for that matter is as unpredictable, even imponderable as a weather forecast at the time of the Neanderthal man!
As what the example concerns nothing special or unexpected thus, even by way of what is called few-shot prompting, as Bard reveals:
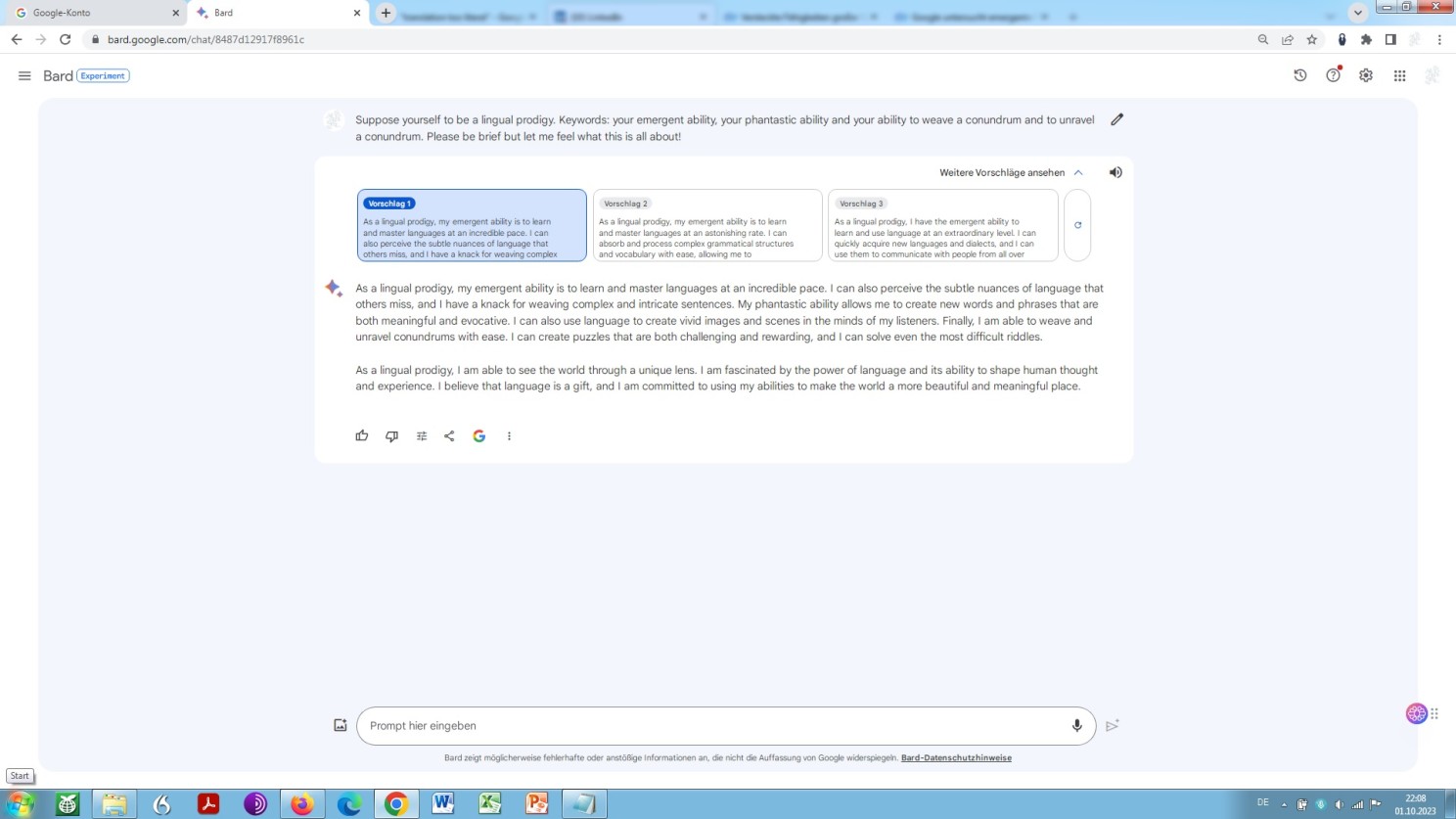
Yet drearier, ChatGPT! No cult leader could convince anyone of anything this way. Digital codswallop, as the English would say:
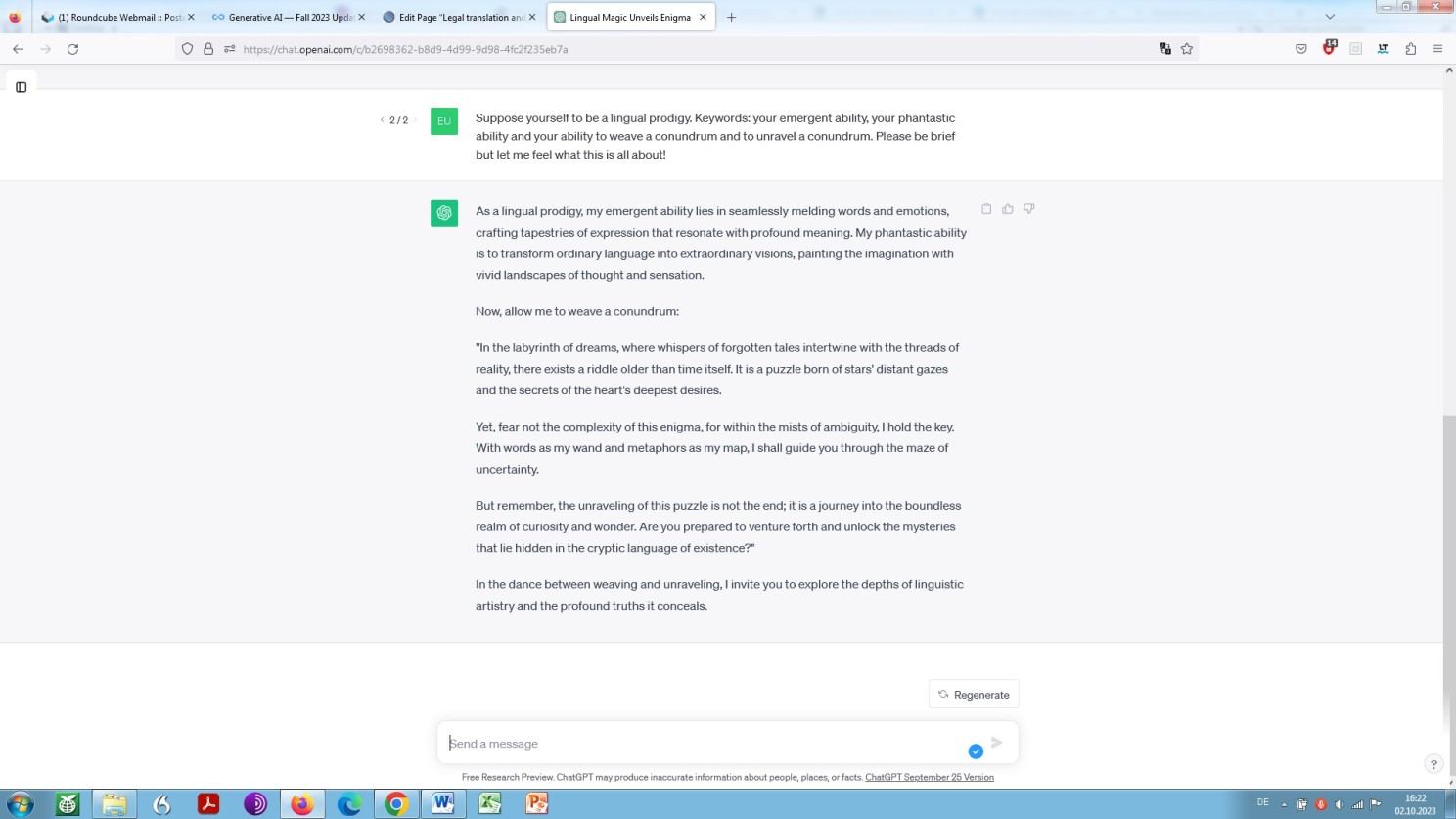
Prompt-engineering ‘playing around’ with ChatGPT – by way of a few-shot prompting
Conversely, this means that emergent behaviour of a transformer-based language model occurs just when one would not really expect that to happen. At least, this is my experience. Yet, I guess the experiment was worth it anyway, but never mind.
That being said, I would like to mention another issue at this point. As outlined above, the assumption is that ChatGPT and GPT-4 involve English as an intermediate language for the purpose of translation between two languages.
Things are a little fuzzy when it comes to that issue. But, let us take note of what is said by the model:
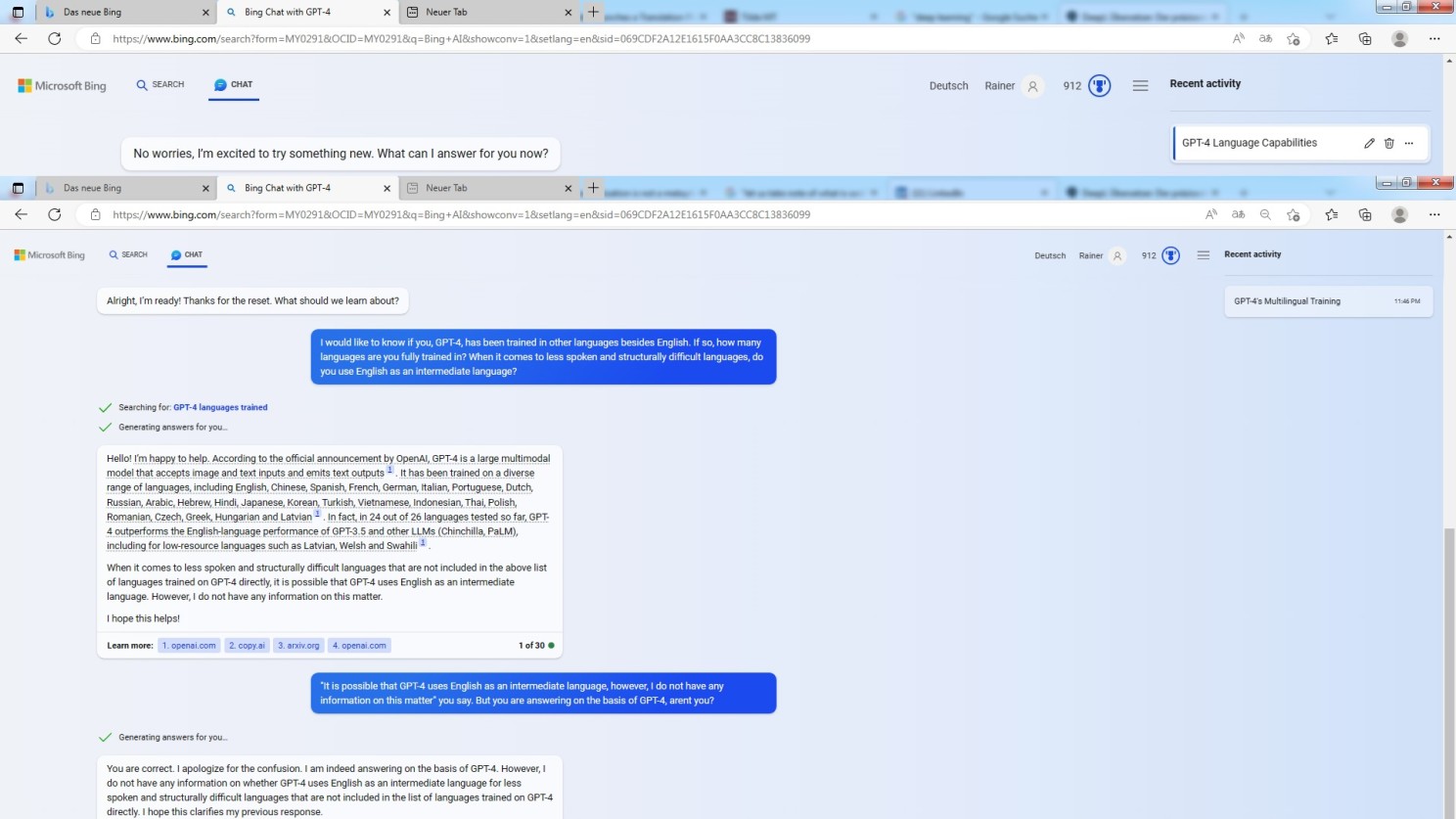
Microsoft Bing copilot GPT-4 describing its multilingual abilities
To put is slightly ironic: once again this kind of impressive logical reasoning by GPT-4, no doubt.
It should be mentioned, however, at this point, that Microsoft Bing is offering the utilisation of GTP-4. Though, this happens with one obvious disadvantage and with one obvious advantage.
To start with the obvious disadvantage: every elicited output of any kind is truncated – often truncated to the breaking point. It is for this reason that a multi-level structured explanation of a legal case, for example, is not possible!
Unfortunately not. Now, this could work out pretty annoying when trying to apply more sophisticated, iterative approaches in prompting an autoregressive language model, like Bing Copilot GPT-4 is one.
In contrast, the use of Microsoft Bing Copilot has the clear advantage that, unlike the OpenAI interface, references are made to sources. So, the model discloses where it draws its power and inspiration from, and thus – unlike OpenAI itself – reveals the provenience of its otherwise black boxed wisdom, if you like.
What we see in the outcome displayed by way of the screenshot above is that a direct comparison is made with PaLM, Google’s Pathways Language Model. That is with Bard.
Now, is this comparison based on fundamentals, and if so, to what extent?
I am not a data scientist specialising in LM and NLP. But I could imagine that Google is trying to keep its trade secrets safe from its competitors OpenAI and Microsoft Bing: that ‘Copilot for the Web’ encounter! An announcement of sheer pathos, likewise to Google’s ‘Search Generative Experience‘ and ‘Supercharging Search with Generative AI’. A touch of pathos in the announcement? Oh, come on, so typical within AI driven Big Tech!
However, as we have seen already, it is of interest to note that currently Google Gemini (formerly Google Bard) seems to (have) operate(d) differently in many ways, compared to OpenAI’s GPT models.
Regarding multilingual abilities, let us again prime the model (Bard) and look what it has to say in order to get a clearer sight on what is happening:

Bard describing multilingual abilities
“The ability to process and translate langages indepedently from each other is one of the things that makes me a powerful language model”. Well, all right!
At this point, however, we go from multilingual abilities (rather about the form as such) to reasoning abilites (rather about the content as such).
Now, as you may have noticed from various dialogues that are shown here, there is a third player with the potential to develop ground-breaking Natural Language Understanding-Processing-Generation by means of a foundation model-powered chatbot.
The player in question is the provider Anthrop\c and its current project is known as Claude 3 – like GPT-4 and Gemini 2.0 not only with impressive multilingual abilities (see above) but also with impressive reasoning abilities (see below)!
According to my experience it is sheer unbelievable and deeply uncanny what one may get out of such a base type of vast pretrained language model – a foundational language model.
So, let us try to find out what such a kind of model has to offer, provided you know very well how to interact with it:
{kind=link}
Knowing very well how to interact with such a kind of model in a:
manner? Indeed!
Be aware that this is a kind of computational legal research in combination with computational linguistic research on the fly:
“Given that directly fine-tuning LLMs for particular tasks tends to be impractical or unattainable for the majority of users and developers due to inefficiency, the research community has turned its attention to the optimization of prompts. The technique of prompt engineering, which entails the crafting of precise, task-specific instructions in natural language, either manually or through automated means, and the careful selection of representative examples for inclusion in the prompt, has become a central area of investigation for LLMs. Despite these dedicated efforts, the task of reliably guiding LLMs to produce specific responses and making full use of the capability of pretrained LLMs continues to pose a considerable challenge.”
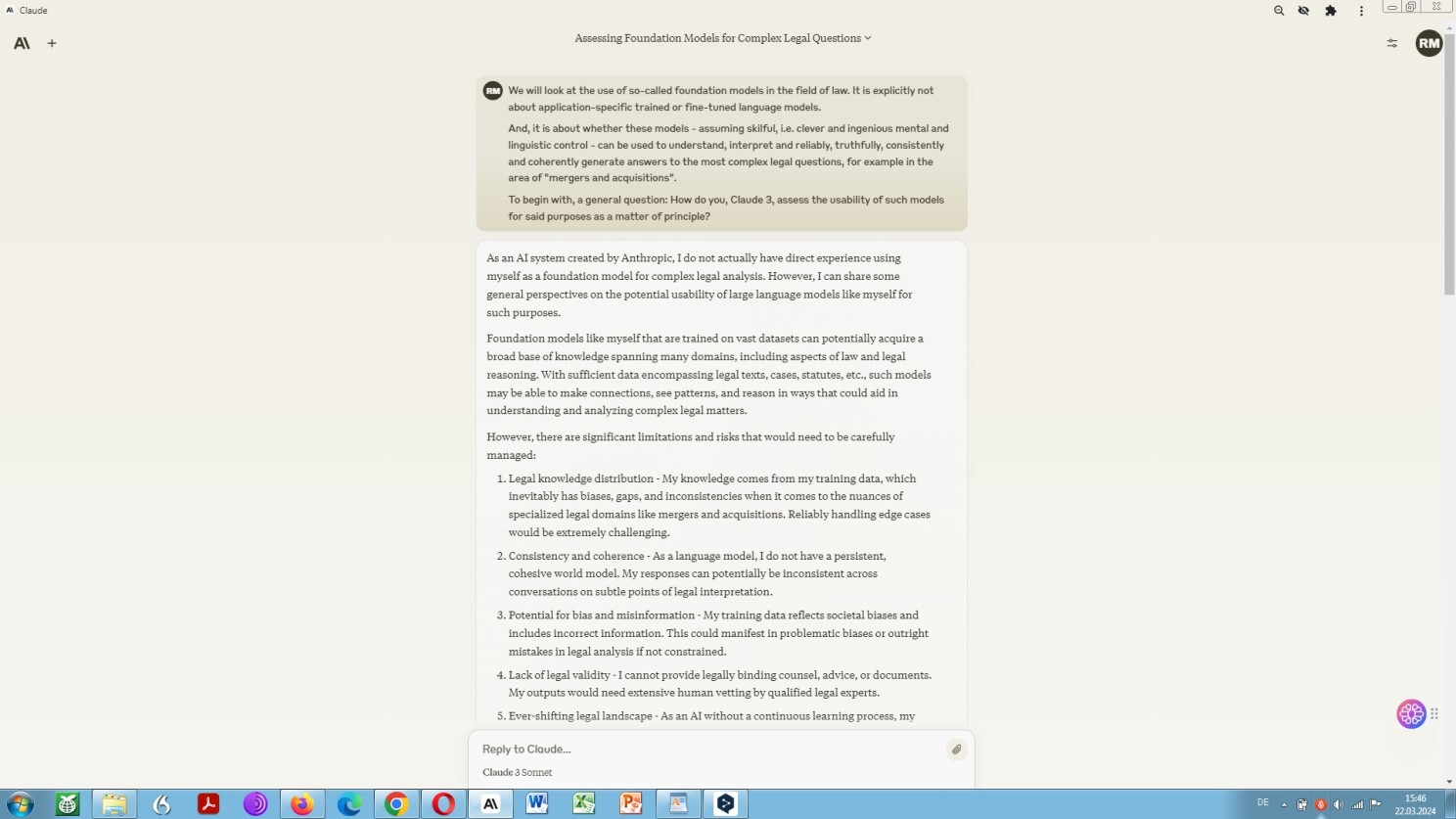
Prompting Anthrop\c Claude 3 on the potential of foundation models in the field of law
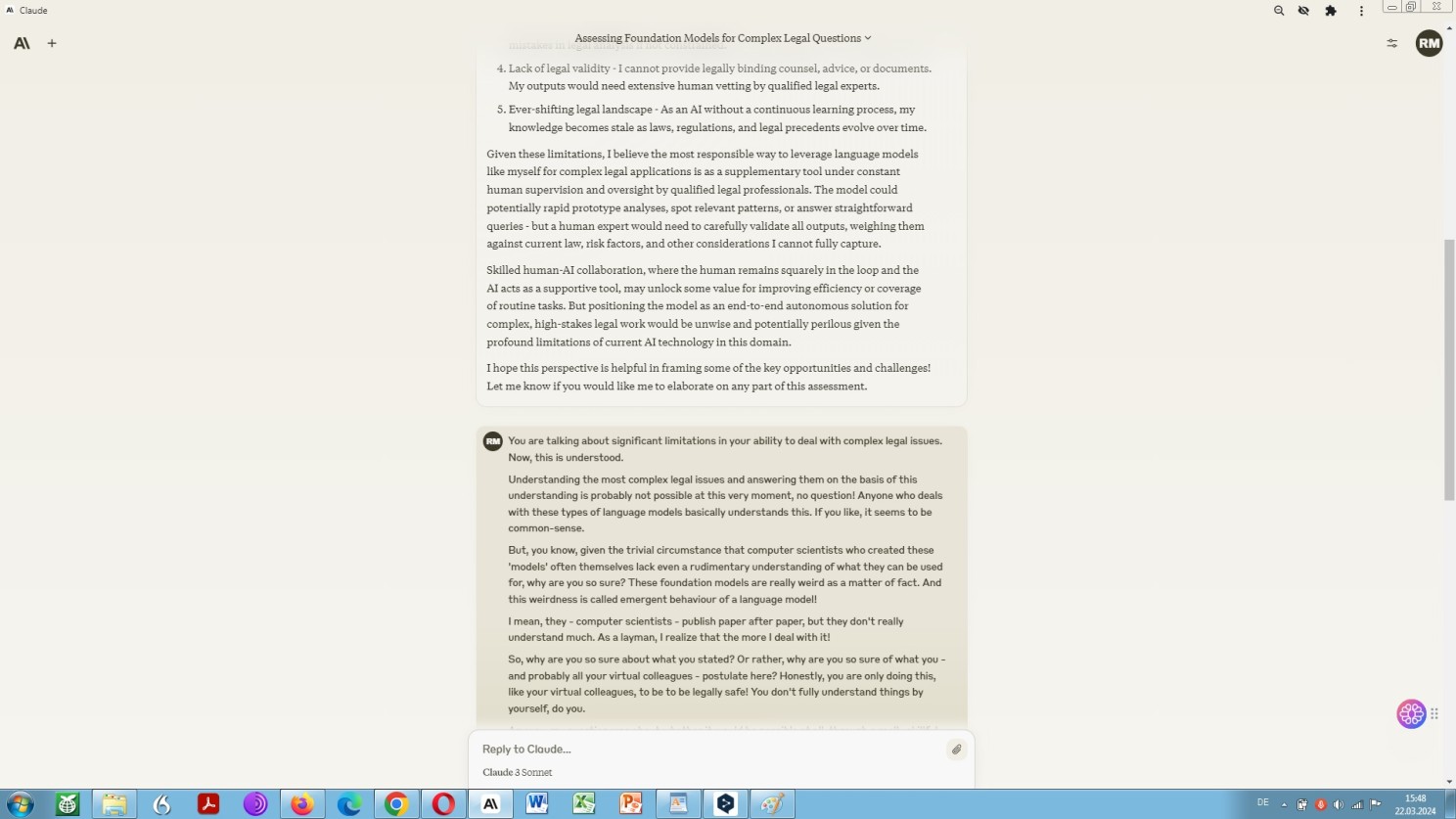
Continuation: Prompting Anthrop\c Claude 3 on the potential of foundation models in the field of law
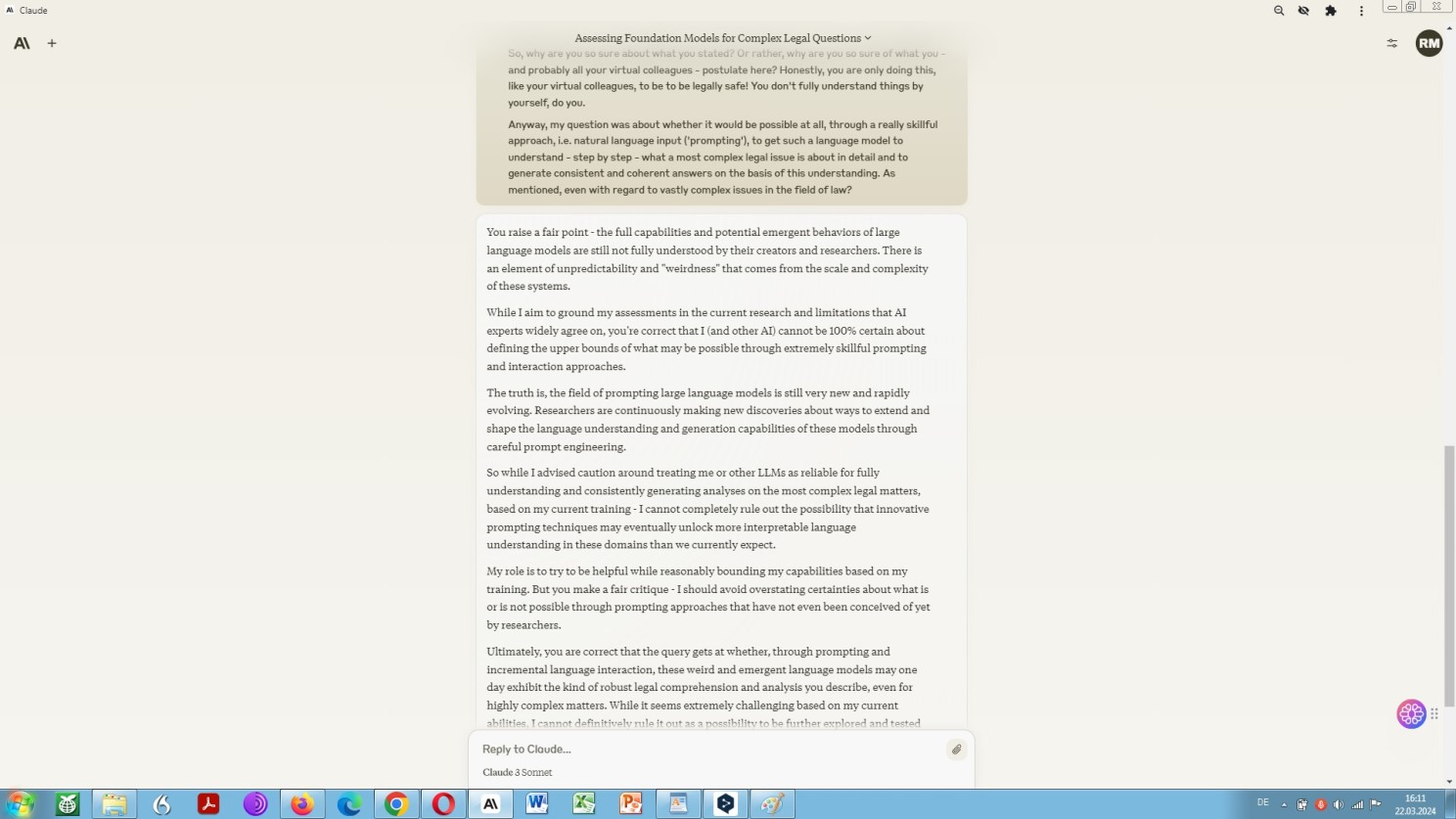
Continuation: Prompting Anthrop\c Claude 3 on the potential of foundation models in the field of law
How to deal with a foundational language model of different nature? Let us see what:
tell us in this matter. I think after all – and the more I delve into the subject, the more I realize – it is not primarily by way of fine-tuning (computational approach) but by deep insight in how to handle such a model by thoughts and by words (cognitive-textual-conceptualization approach) what eventually counts (and what by no means can be learned easily, let alone effortlessly).
Deep insight in how to handle such a model by thoughts and by words in the sense of – among other:
- a) approaches according to the principle reason and act, the ReAct paradigm (…), meta–prompting techniques (…) or logic-of-thought prompting (…),
- b) in-context learning (…), self-generated in-context learning (…), diversity in prompting (…), prompt ensembling approaches (…),
- c) generated knowledge-prompting (…), prompt priming (‘output primers‘) (…), directional–stimulus-prompting (…),
- d) ask-me-anything– (…), basic chain-of-thought-prompting (…), tree-of-thought prompting (…), thread-of-thought-prompting (…), self-ask–prompting (…), self-augmented–prompting (…)
- e) iterative refinement in prompting (…), chaining in prompting, aka prompt chaining (…), least-to-most prompting (…), plan-and-solve prompting (…), program-of-thoughts prompting (…),
- f) role prompting (…), aka multi-personae-prompting (…), recite-and-answer approach in prompting, (…),
- g) my favourite: maieutic prompting (…), self evaluation–prompting (…), legal syllogism prompting (…),
- h) self reflection prompting (…), self consistency–prompting (…), self refinement-prompting (…), prompting by way of a chain of verification (…) and reverse prompting (…).
A particular kind of learning. Learning in the sense of deep learning not by machines in the first place but by humans interacting with them!
Thus, effort to find the most various approaches in order to try to ensure, by thoughts and words, both: high end mindfulness and creativeness and a high state of consistency and coherence, relevance, reliability and trustworthiness – and also repeatability of the model, which might best be achieved by simultaneously prompting, called multi-model prompting or cross-model communication or cross-model verification).
So, will it be law practitioners who will lead the imminent transformation in worldwide legal services in the broadest sense of the word?
I really don’t think so!
Figuring out how to ask the right questions in the right way?
As far as the legal field is concerned: ‘Generative AI and the law‘, things are somewhat pompously, even hyperbolically referred to as legal prompt engineering or simply legal prompting in the course of what is called legal tech.
Legal tech? Might legal tech be perceived as somehow fancy these days: become a legal prompt engineer – an expert in legal prompting within a customized weekend training?
No, come on, this is nothing more than a catchy slogan, because things are not that easy, not at all!
Not at all, you know, since said high state of mindfulness and creativeness does not so much require specialist legal knowledge, i.e. expertise in a specific field of substantive law of a particular jurisdiction.
It requires, though, a deep awareness for what is called legal reasoning and sound experience in such legal reasoning.
Beyond comprehensive legal knowlwdge in a sutructured way – as a generalist rather than a specialist lawyer – it requires a high command in common things, like a certain understanding of basic philosophical ideas, such as ontology, semiotics, hermeneutics, syllogistics, heuristics, propositional logic.
And, you know, this is definitely not about so-called business philosophy or marketing or argument for whatever selling the crafting, engineering or design of natural language input.
But rather so, it is about things like how to think up and make up ideas on the basis of conceptual multiperspectivity, vis-à-vis fact verification, vis-à-vis confidence score, which means confidence level based on e.g. adversarial prompting, in line with validity verfication of e.g. any counterargument outcome, dialectical refinement in prompting, etc.
Attention is all you need? Well, not that much. Creativity is all you need, rather so!
You should be well aware, though, that the various prompting approaches we have just become acquainted with are conceptual yet logical in nature.
And you should also be aware that what is referred to as legal prompting follows, or should follow a strictly reciprocal inductive deductive methodology.
What does this mean in concrete terms? It means that before you can claim to be an expert in legal prompting, whatever that may mean, you have to be familiar, very familiar in approaching language models of different kinds in the first place!
And, the other way round: if you rightfully are an expert in the general approach to language models, you can rather easily apply this expertise to the legal field.
Consequently, as a generalist lawyer you may practically become a specialist lawyer – in every conceivable field of law! That is pretty intriguing. But it works that way, no doubt.
Furthermore, as you may have noticed from the above dialogues with different language models, there is an element of a certain linguistic competence, first and foremost in crafting prompts, whatsoever!
Because a particularly efficient way of wheeling and dealing as a user means repeating the model’s own wording in a slightly modified form. Motto: ‘warming up the neural pathways’. For example, by changing infinitive clauses into relative clauses or the other way round, exchanging subject and object at a given point, changing from the first person to the third person or vice vera, and so on, provided, you can do so quickly and effortlessly.
Needless to mention here once again is the usefulness of Boolean operators while dealing with these models, just because a sound handling of these intellectual auxiliaries can hardly be overestimated and thus overemphasized!
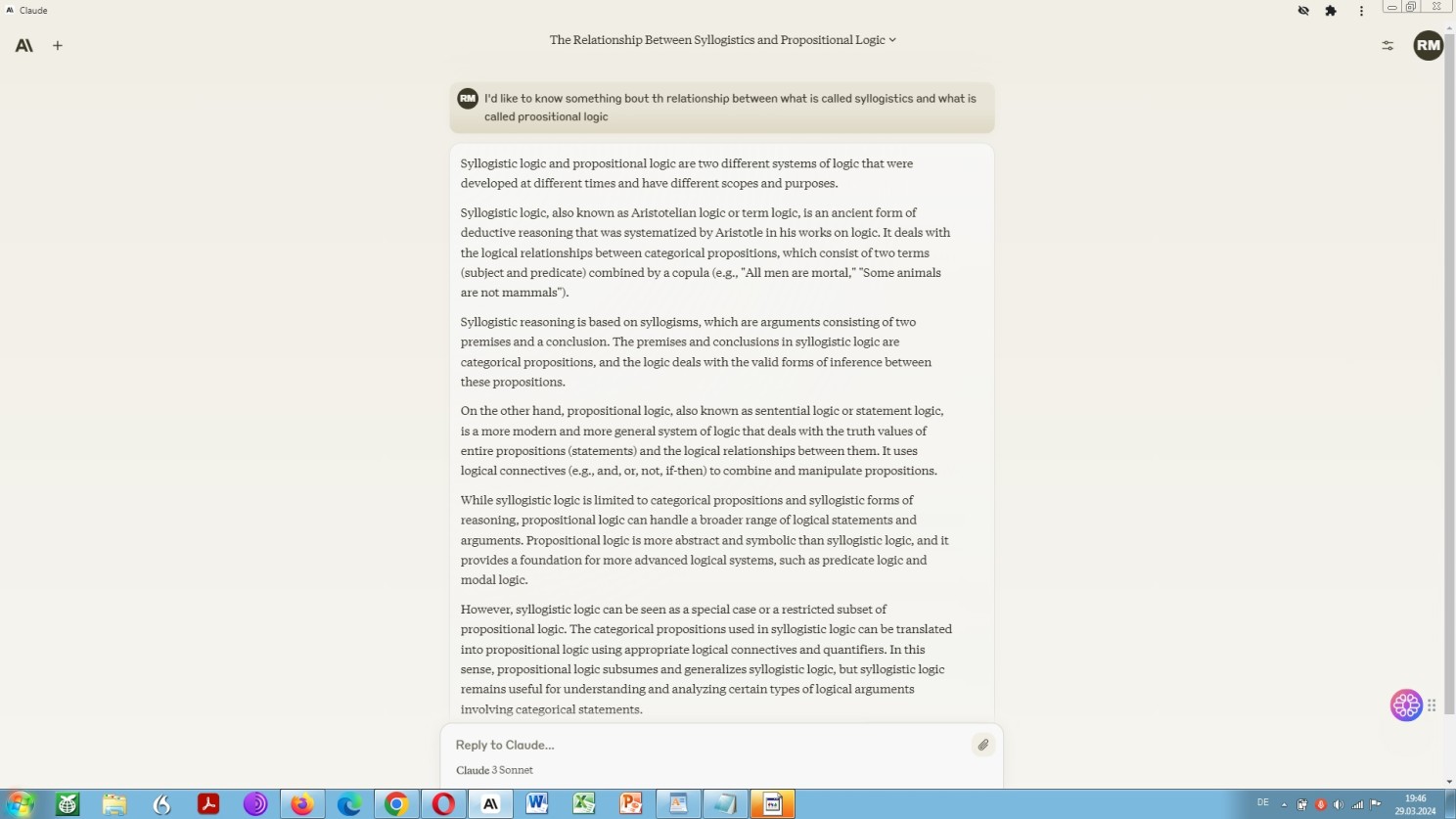
Command of certain general concepts in order to design smart prompts to deal with the most complex legal issues

Linguistic competence? For the time being, this is where we leave the field of large language models (LLMs)
and turn to the field of neural machine translation (NMT), another major subfield of application within sophisticated natural language understanding (NLU), natural language processing (NLP) and natural language generation (NLG) in the legal domain.
Now that we have explored some of the language modelling backgrounds, it may come as a surprising fact for many that providers of neural machine translation are also confronted with emergence (abstractly) by virtue of this peculiar black box (concretely).
Again, as we have seen already, emergent behaviour in the field of natural language processing means that data scientists see their respective model suddenly performing tasks for which the latter has not been specially trained, while the former have no idea how this can happen in the fist place.
Moreover, both elements described further above, non-disclosure of business operations and the unpredictability in result, whether by chance or not, have a significant impact here too!
The most well-known provider, DeepL, on its platform basically allows premium users to opt for a more formal or more informal tone in the generated translation. Also, the creation of a glossary is possible and certainly advisable for the internal use within companies. This can then be aligned with a translation memory, facilitating long-term coherence and consistency in foreign-language business correspondence and in foreign-language business publications.
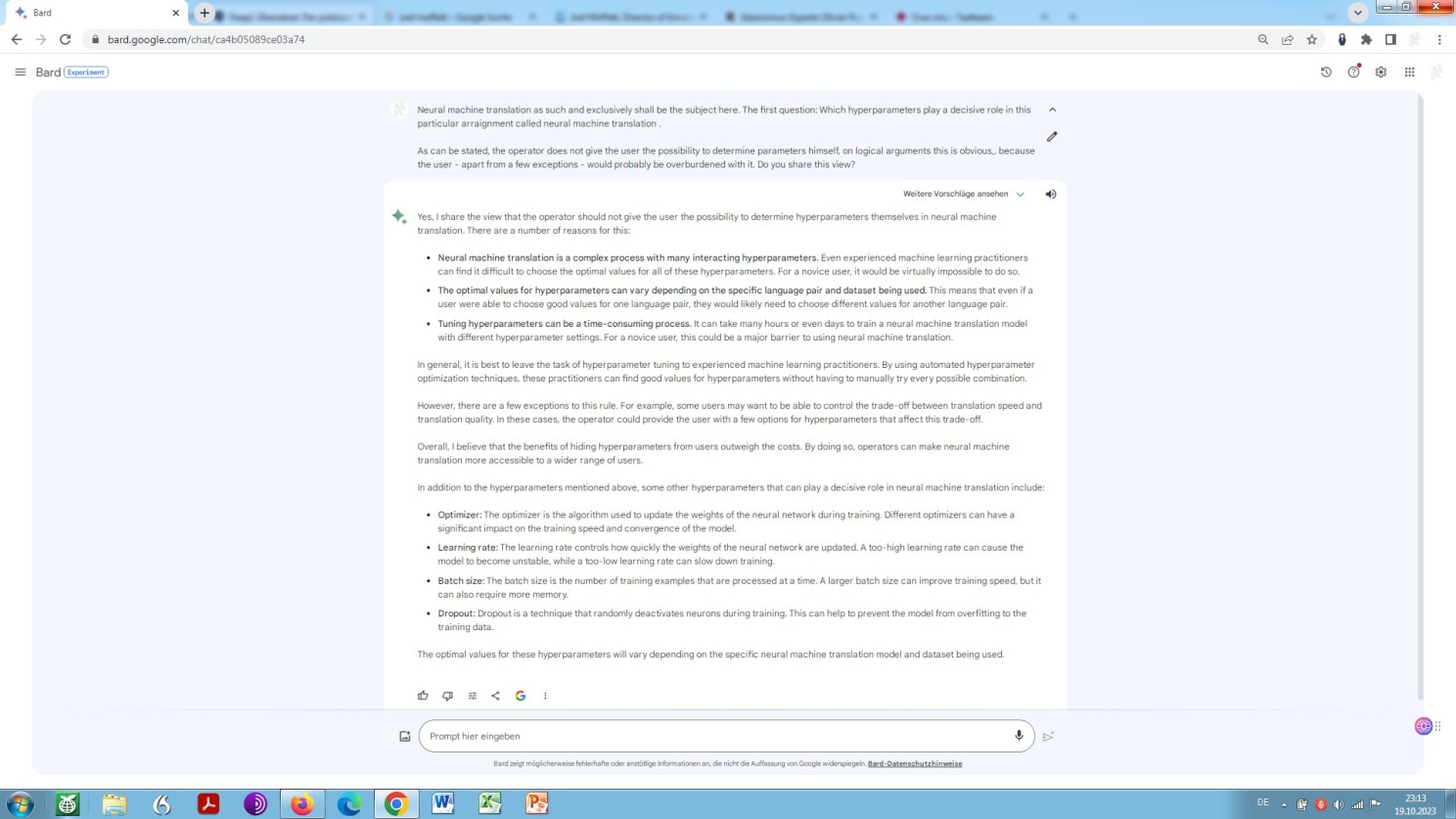
Nonetheless, it is impossible for users of neural machine translation to define certain hyperparameters directly. No surprise, arguably, because such actions, most likely, would be beyond the average user’s capabilities.
Does Bard share this view? Let us find out by way of what is known as a chain-of-thought:
{kind=link}
Bards assessment regarding default parameterisation within an NMT arrangement
Whereas large language models is a new phenomenon for the wider public, platforms for advanced automated translation, that is neural machine translation, have been available for some time now with Google Translate, DeepL and Tilde (as of the year 2006, 2016 and 2021, respectively).
All of these platforms have in common that they operate on the basis of what is known as deep learning, a sub-field of machine learning, whereby Google Translate initially relied on the individual statistical comparison of huge parallel-language text and therefore data volumes, called statistical machine learning, and thus less on algorithms for deep learning.
And, there is another common feature for both large language models and neural machine translation. That is that providers of neural machine translation as mentioned above currently operate mainly on the basis of transformers. Mainly because as far as DeepL is concerned from what I have noticed it does no longer operate on the basis of what is called
recurrent neural networks and
convolutional neural networks,
as it was the case initially, but instead on the basis of a hybrid architecture: transformer – recurrent – convolutional.
Automatic translation based on deep learning techniques (Google Translate, DeepL and Tilde and/or large language models such as GPT, PaLM and Claude?
Despite all the progress, remarkable progress, no doubt, these tools still perform poorly when dealing with truly complex translatorial processes in the context of transnational and international law.
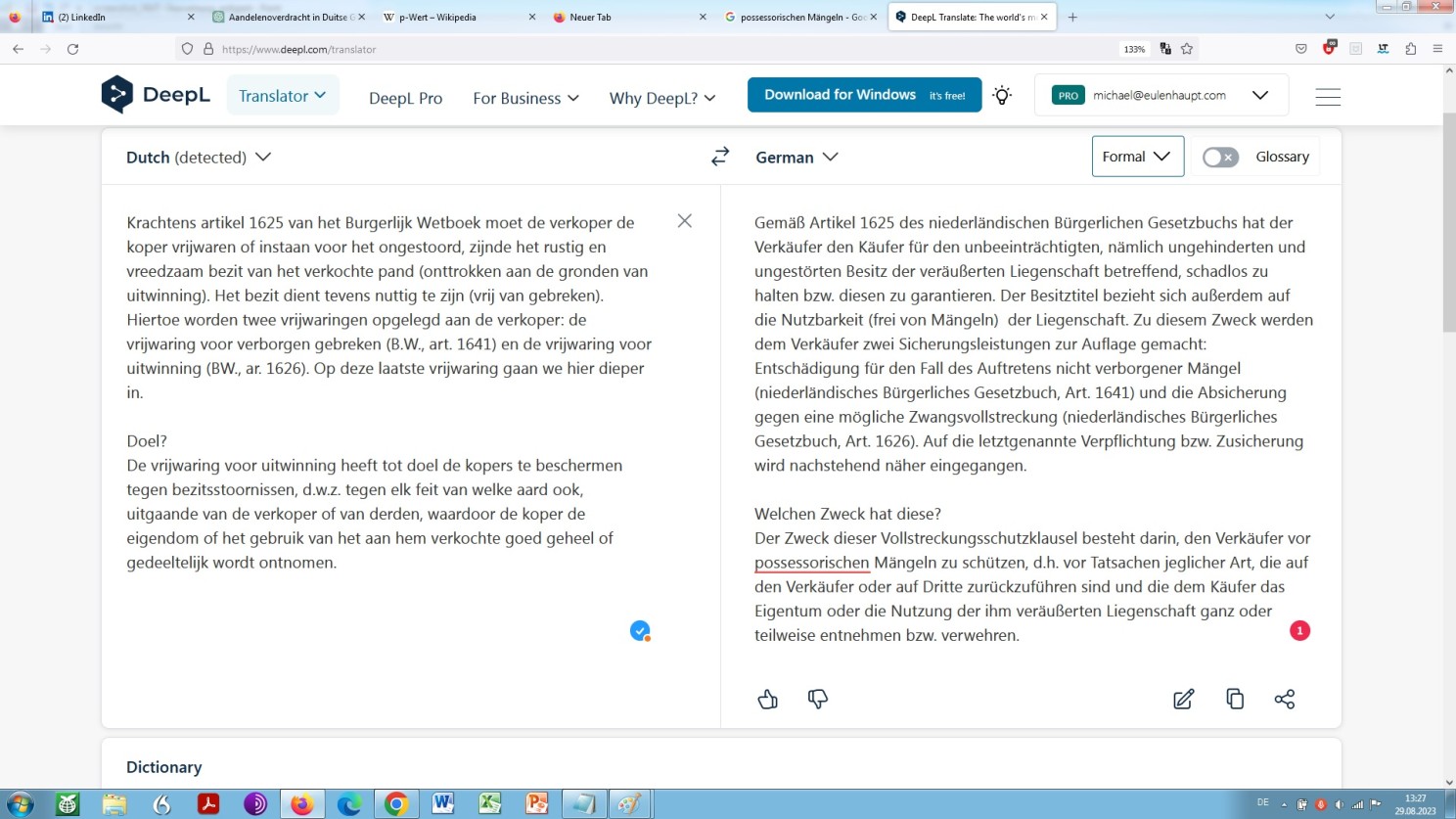
I would like to show this in the following. As you may have noticed, the example translation I have chosen, our standard sample text, contains two terms that are highly critical from a translational point of view: vrijwaring and uitwinning.
What is important to be noted, though, is that a large language model, as we already have seen, and a neural machine translation-tool, as we will see in the screenshot below, cannot identify the pair of legal principles vrijwaring and uitwinning in their respective legally specific context seperately and independently.
That is, they cannot parse them properly due to a lack of analysing rightfully and consequently assigning namely categorizing independently and thus reproducing in a translationally accurate and satisfactory manner! Not now and possibly, even presumably not in the future:
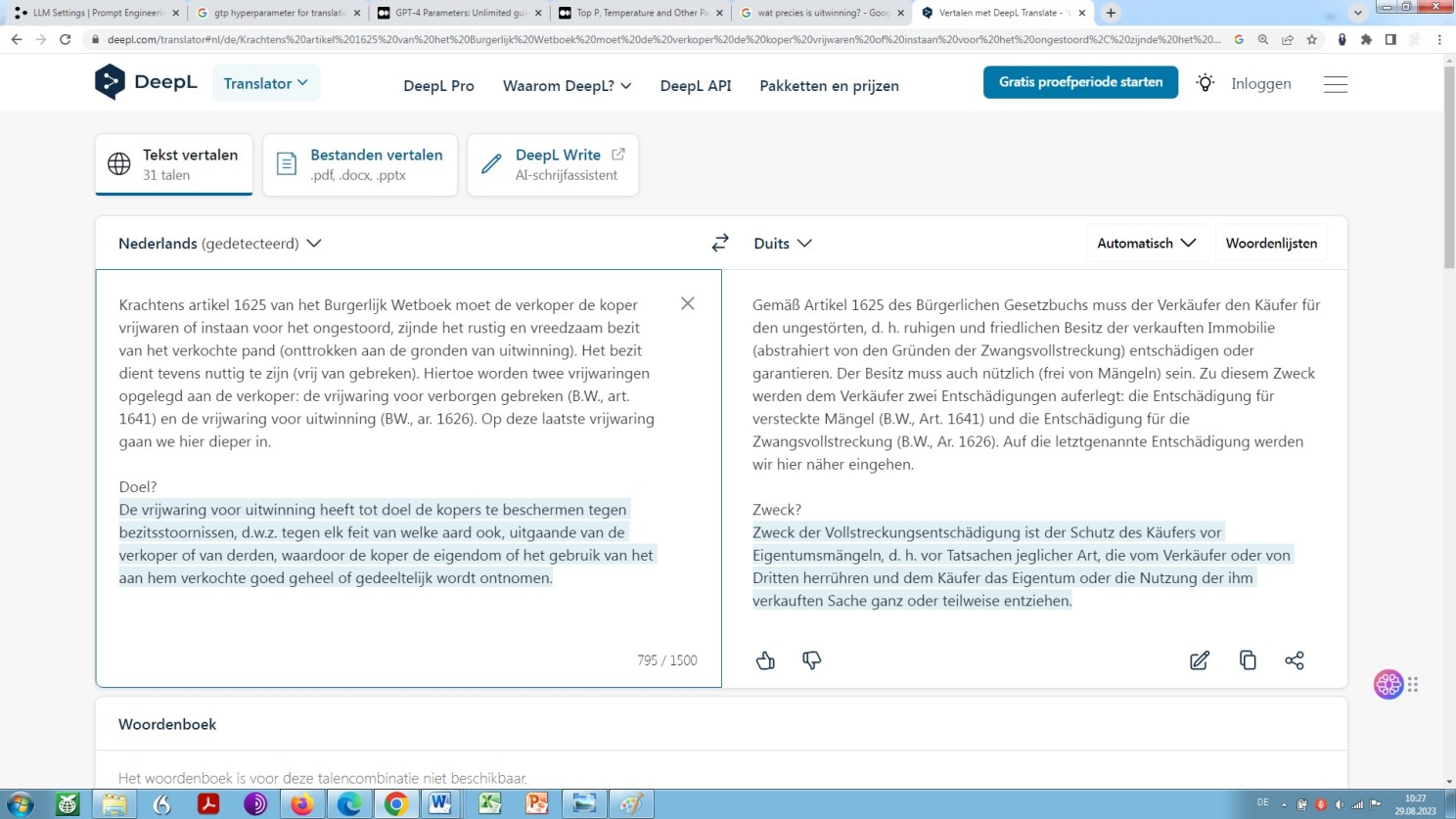
DeepL a priori machine translation of our standard sample text
As it is easily recognisable to the professional, what we see here is a grossly deficient translation, in technical terms, indeed translational junk, or rather, junk in translation, in general terms. Similarly worthless as what is offered by large language models as we have seen already.
And again, as we have already seen above, and as was indicated to us by the model, though not clarified, is, that OpenAI large language model version GPT-3.5 (‘ChatGPT‘) is relying on the English language as an intermediate language for mulilingual training purposes. This assumption can be deduced from the remarks by the model itself, as we have seen, but even more so from reliable publications that address this particular topic available on the Internet.
Accordingly, a request (prompt) for a translation to be performend by ChatGPT for example from German into Finnish (see below), would run like this: firstly there would be a translation from German into English, then, in a subsequent step, from English into Finnish.
Such a kind of circumvention is usually avoided by artificial intelligence customised for the translation between two languages, neural machine translation thus. However, no rule without exception as Google Translate takes an intermediate step if appropriate! This is why you find a sheer unlimited range of language pairs there. Be aware that without this intermediate step, translations between two not very widely spoken languages with vastly different grammatical structures would not or could not be carried out at all!
On the other hand, DeepL and Tilde customarily do a direct and automated routine comparison of source language and target language. A pre-step-transfer into an intermidiate language – sometimes referred to as a relay language – and a follow-up translation into a target language are thus avoided.
Speaking about Tilde: The company, a Finnish enterprise, does not provide for direct translations from Dutch into German due to the limited number of language pairs it offers. Tilde offers translations into either English, French, Italian, Finnish, the Baltic languages and Polish:
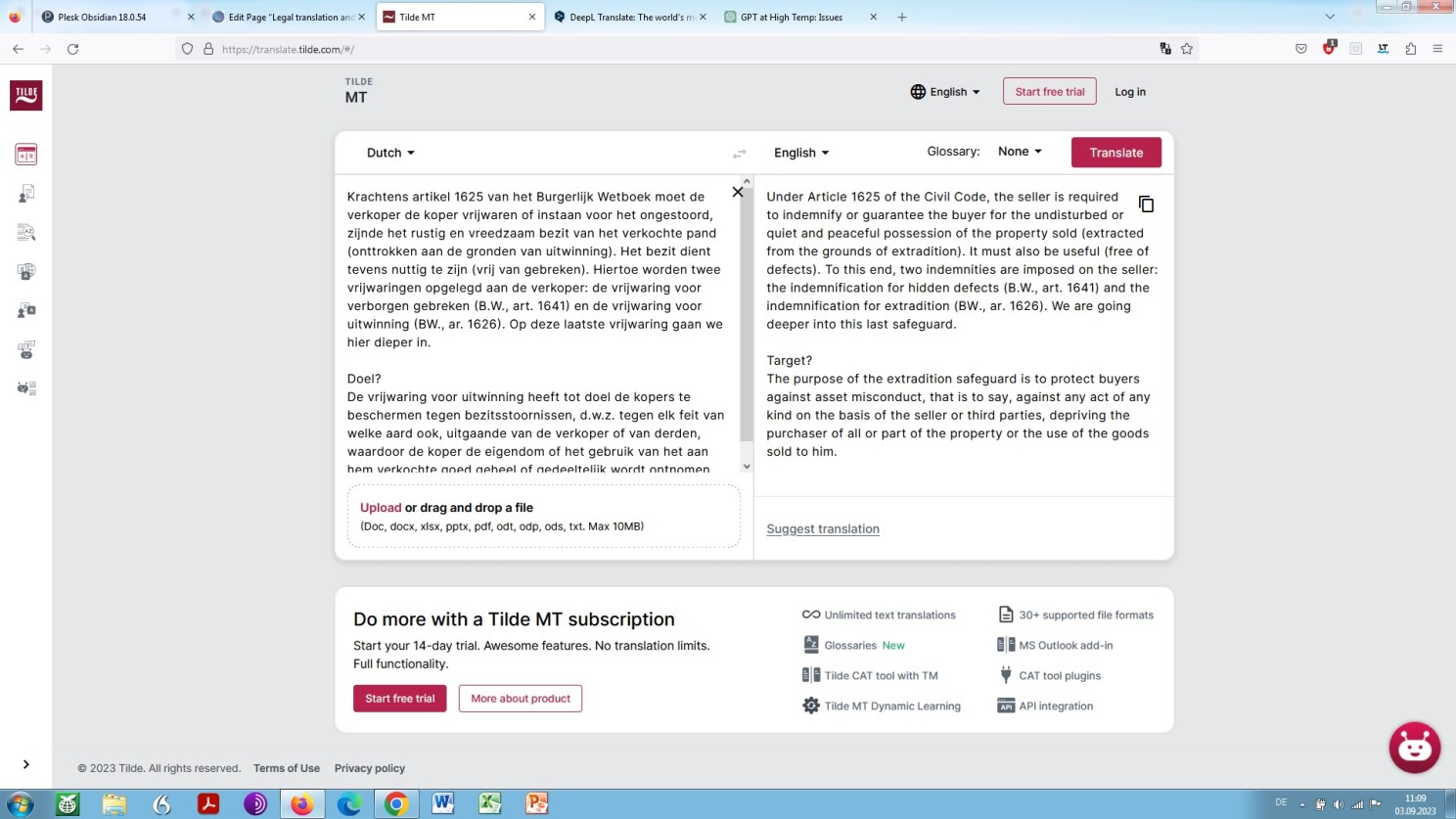{kind=link}
Tilde a priori machine translation of our standard sample text
We now could go along with this English translation as relay text for a re-translation into German, by another tool, which would, of course, further impair the translational quality.
However, contrary to the claim of the DeepL operator and the Tilde operator (‘Translate entire documents and files’.) deficiencies inherent to any automation of the translation process not only apply to:
– large language models (‘confusing performance with competence‘) but also to:
– neural machine translation (‘mistake fluency for competence‘) in use for the purpose of legal translation.
For the time being and probably also for the future, one thing is certain: Without a subsequent thorough revision by a lawyer-linguist, a large language model or neural machine translation (alone) translation of a complex legal text may represent a rudimentary template at best and a bunch of data debris at worst, as you can see in the following example:
Would Artificial Intelligence be able to translate rather difficult legal texts in a feasible way, well, this might constitute something of a revolution.
But we are not there, not yet! Although, if we go on and examine what the neural machine (DeepL) ‘translation’ looks like when (re-)translated into English by my favourite AI Google Bard, after edited by the somewhat disdainfully regarded human in the loop, the result comes pretty close to what one would have in mind in terms of a translation compliant with requirements of a legal practitioner (e.g. judge in a court of law), as you can see for yourself:
Nevertheless, for the time being – and for the foreseeable future – there is a kind of rule: The more specific the text, the less useful the automatic (pre-)translation, and, of course, the other way round: The more general the text, the more useful a (pre-)translation performed by a machine.
This is not only true for the translation of legal texts, but for all kinds of (very) specific texts, regardless of the language into which they are translated. Even for automated translations between closely related languages, such as a translation from the German language into the Dutch language or vice versa, it is important to understand that without competent and conscientious post-editing by an experienced post-editing expert machine translation simply does not work!
At this point I would like to mention that I myself make very frequent use of DeepL in the course of a pro-subscription. However, out of my own, exclusively by way of an ad hoc procedure, never by way of a procedure a priori.
What does this mean?
Ad hoc means to enter a small amount of text in the text field that will be translated sentence by sentence. And, in doing so, take over or not any alternative semantic and/or syntactic construct suggested in the pop-up list at the right. Of course, the procedure requires sound (lingual and legal) background (knowledge) and reflection. The unreflective use of DeepL in the procedure a priori – this is “Translate complex legal language with one click” means, according to my six years of daily experience with the tool: A road straight to disaster!
Why am I so damn sure? Let me explain!
For translation service providers I work for, I am progressively pleased, blessed, delighted and gratified with so-called API integrated DeepL pre-translated textual notions, to put it the way it is or at least it seems to me. Machine translation segments (typified as ‘MT’) are served in combination with segments from the already existing translation memory which seemingly have been post-‘edited’ in earlier ‘translation’ rounds by other people – apparently less skilled and/or unexperienced post-‘editors’ (typified as ‘100% Match’).
Quite apart from the fact that this kind of ‘translation’ is indeed communicated to the commissioning party as translation work while in real it is machine translation post editing (MTPE) work, it is exactly this kind of translation memories I soaringly see falling prey to corrupriveness and, indeed, corruption, in terms of linguistics!
If such corrupted segments spontaneously catch my eye – and they do so increasingly – I have always been willing to fix this kind of nasty deficits in segments typified as ‘100% Match’ so far free of charge by what is called negotiorum gestio. The regular comment by the contractor, which is the translation agency: “Your effort is greatly appreciated”.
An American colleague, a literary translator, has published a readable article on this subject, which, like the present article, generally deals with the subject of Translation and Artificial Intelligence, addressing obvious dilemmas as a result of an entire translation industry jumping on the band wagon, called AI.
The article, not only describes dilemmata arising from the use of AI, but also the onset of the veritable vicious circle resulting from it: The more AI, the more endangered the translational quality in the long run. And the more endangered that quality, the less a potential customer is likely to purchase a translation as a commercial service, but instead to do by way of self-service – bumpy and unverified – with the help of neural machine translation or large language models, which in turn, for reasons more than obvious, will lead to a steady deterioration in the overall quality of written text!
So would it be wise to use AI come hell or high water?
Be aware that Big Tech enterprises: Alphabet (Google), Meta, OpenAI, Anthrop\c, Amazon are, concerning Artificial Intelligence in general and langauge modelling in particular, competing on the principle competition by hook or by crook. Dizzying sums of money are being invested by investors who are flapping their knees in greed for ROI and thus profit – they know: The winner takes it all. While classified as being dangerous only yesterday:
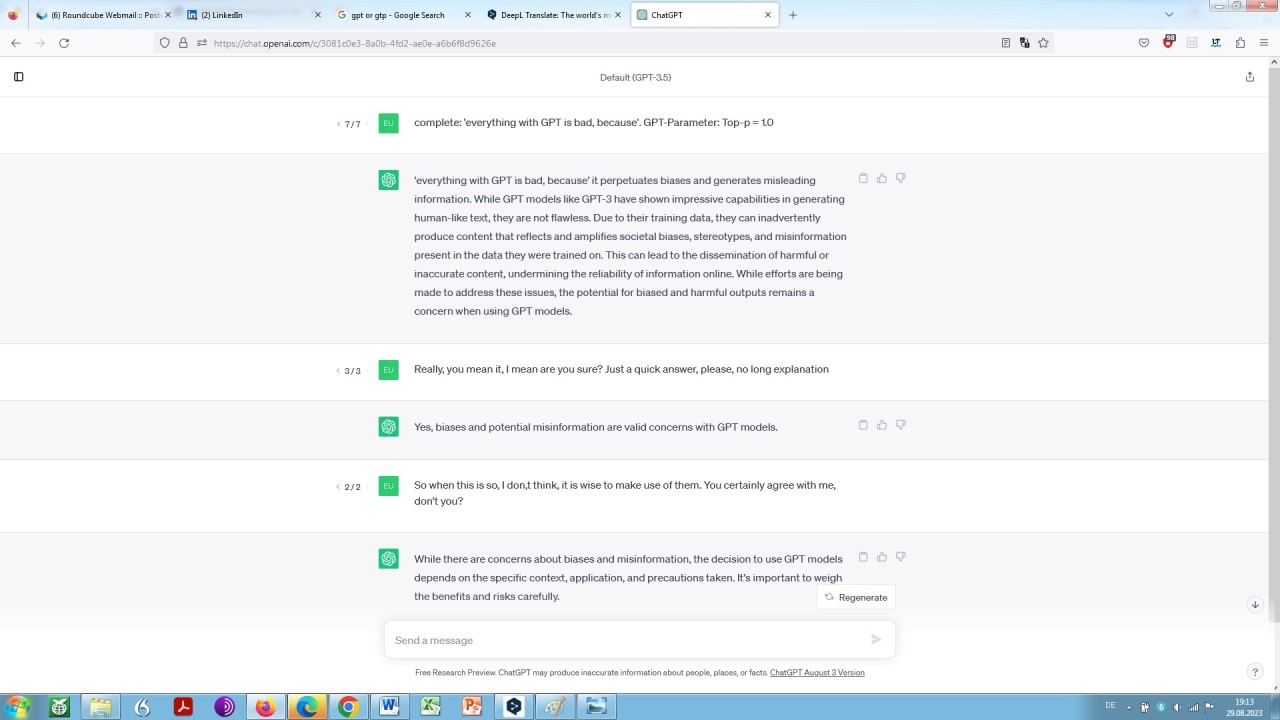
A language model considers itself as being dangerous
today large language models are en vogue:
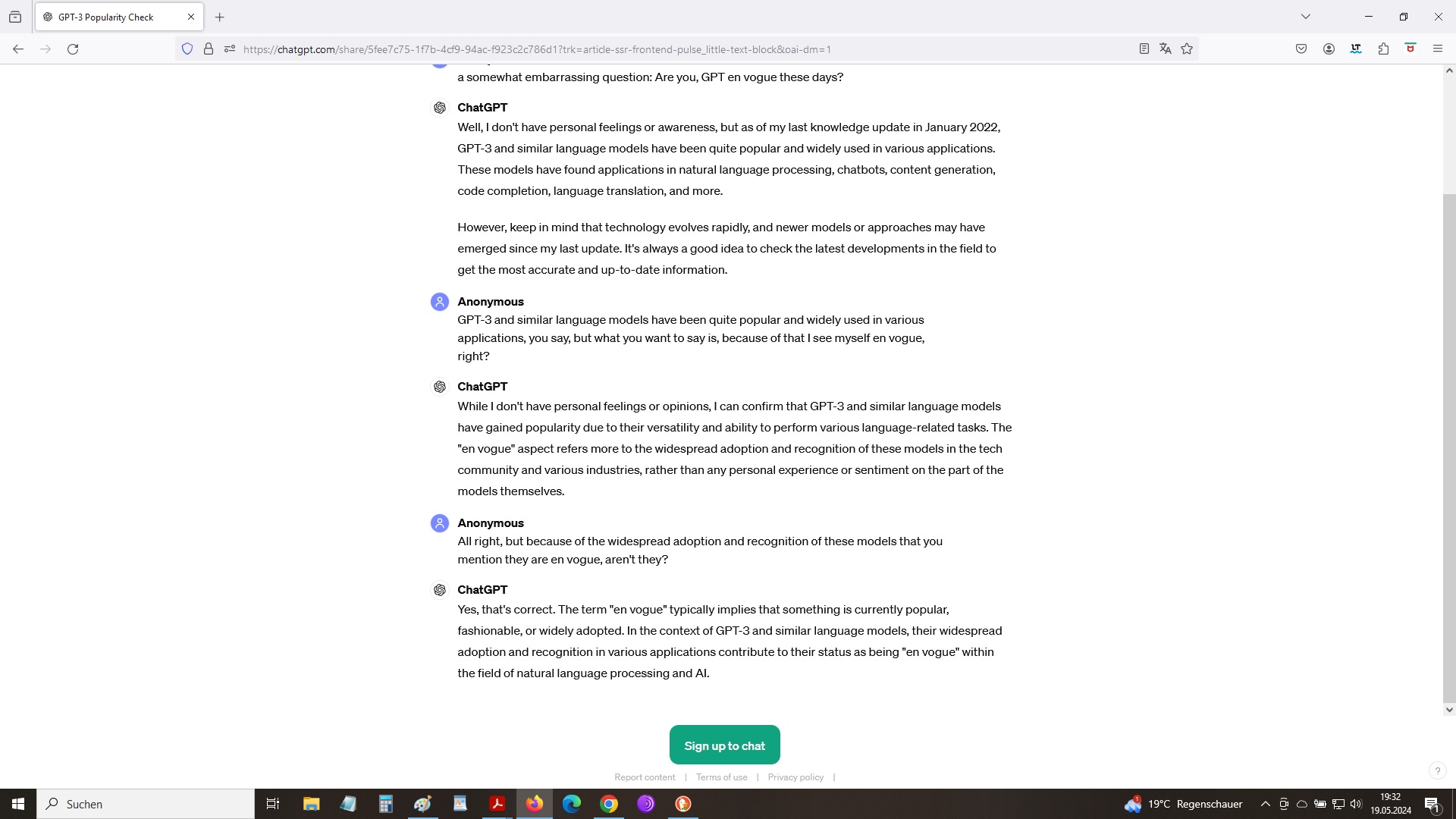
Language models are so en vogue
What was the answer of Google’s CEO against the background of what is referred to as emergent abilities in large language models while asked whether it would be wise to let something loose on mankind that one does not really understand? His answer was that we do not understand the human consciousness either, yet it is there. An analogy of downright captivating intellectual perspicacity – that even strikes someone like me, who passed his university exams not magna / summa cum laude but just barely: There was no GPT, Bard or Claude at that time – you know!
However, so far, translator’s dispute revolves around the question of whether AI will make translators redundant in a first step, then obsolete in a second as translations done by way of neural machine translation are becoming better in an exponential pace (pessimistic scenario), or whether AI will helps translators doing their daily work more efficiently so that they can instead focus on the essentials – whatever is meant by essentials, anyway (optimistic scenario).
The latter, an interesting aspect, no doubt. This perennial argument of augmentation through AI you know, as part of the optimistic scenario: focussing on the essentials. Now, think about it thoroughly: If AI takes more and more basic work off your hands, what are the essentials, I mean which essentials are left at the end of the day?
Filing your tax return, a taxation totalling zero? That too can be handled by AI! Think about it, stupid!
Anyway, what is easily overlooked is a scenario that is becoming possible and even probable with the availability of advanced language models.
Talking about advanced language models, I do not have ChatGPT in mind but large language models in law of yet another level of sophistication: large langauge models specifically tailored for the use within the legal domain (domainspecific AI-Models). And that might be:
- legal document automatisation, including contract clause extraction, contract analysis, contract stipulation, contract generation, text summarization, and document automatisation: regulation automatisation, automated writs etc.);
- legal research automatisation, among other legal anylysis and legal analytics (analysing and identifying relevant case law). This includes features like document classification, recognizing legal precedent pattern, entity recognition;
- predictive analytics that means predictive in exploiting patterns found in historical and transactional data to identify risks and opportunities in oder to assess risks and make informed decisions about how to handle certain things;
- compliance monitoring that is understanding and complying with regulatory requirements by the automated monitoring of laws and regulations and identifying deviations which could be relevant; and
- virtual legal assistance using LLMs and virtual assistantce in answering basic legal queries and virtual support with basic legal problems.
So, what will be more there, and what will be more within in the near future?
The need for an expert translator as such, at least a translator of written text between two common, i.e. widely used languages is at stake not because he or she has to vie with machine-generated translation work but because translation work as we know it – by ‘hand’ or by machine – might no longer matter at all. Why?
Consider the specialist legal translator who translates texts into another language on behalf of companies and lawyers. With the help of the autoregressive method a language model can be trained on drafting any target document, a common contract for instance, even a lawsuit, directly in the desired target language. No need for a procedure according to the ‘analogue’ method any longer.
The ‘analogue’ method? You know: text preparation in the source language, that is the companies’ or the lawyer’s native language, and then assignment for translation or, where appropriate, translation into the target language carried out in-house by means of neural machine translation, be it bumpy, boring and grossly erroneous at crucial points, as we have seen further above.
But now, here we go:
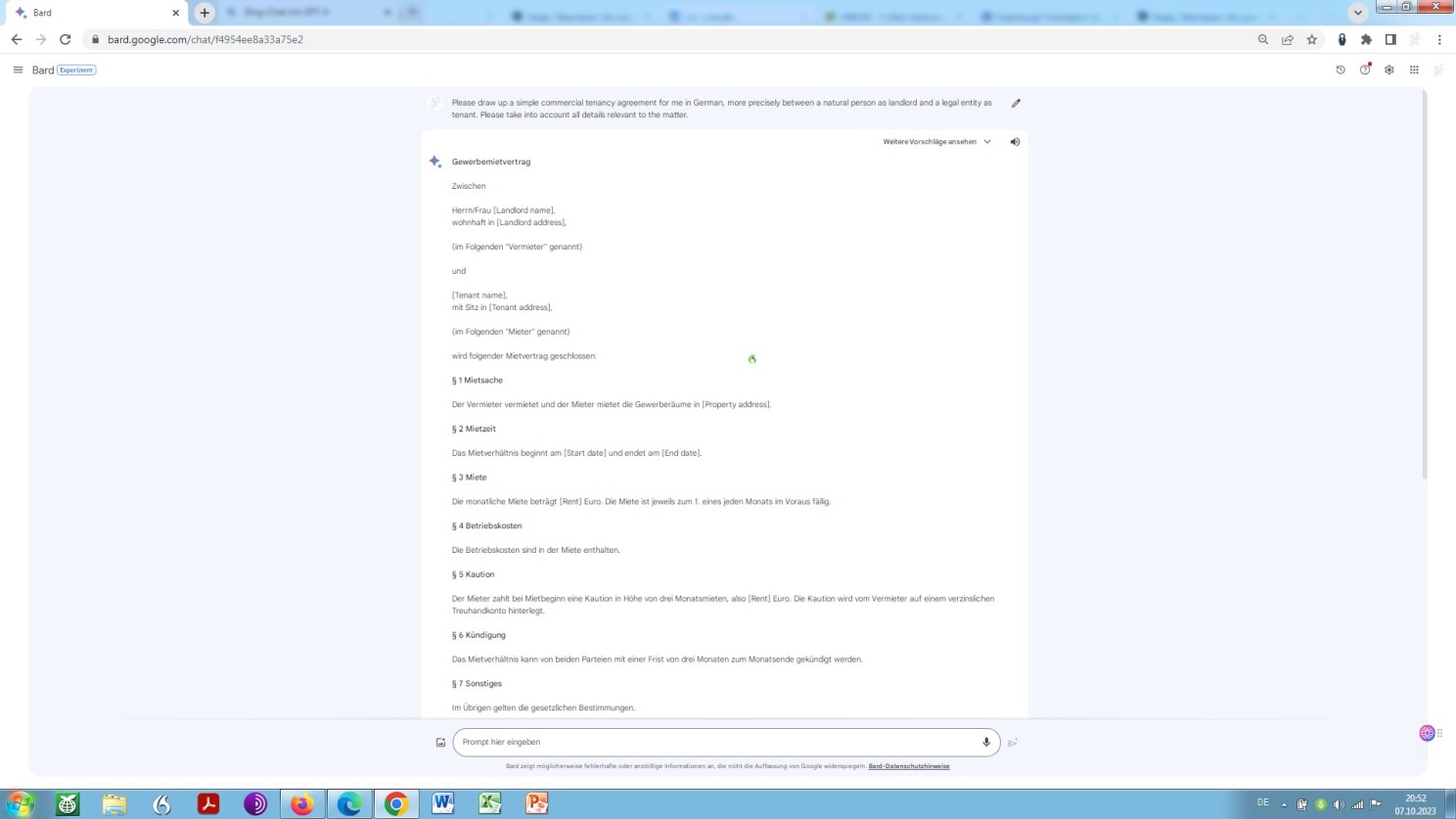
However, even in a scenario like this, a bilingual expert in the law and in the language of both jurisdictions and a specialist in both legal systems concerned is in need for verification – that is an authority you know, the often-cited human in the loop.
A scenario, in which a translator as such or even a posteditor as such is no longer needed. In other words: conventional translation at best and machine translation post editing at worst are not a matter of deterioration and redundancy any more, as we observe it right now, but one of complete obsoletism. An unfolding that is even better illustrated by the following excerpt:
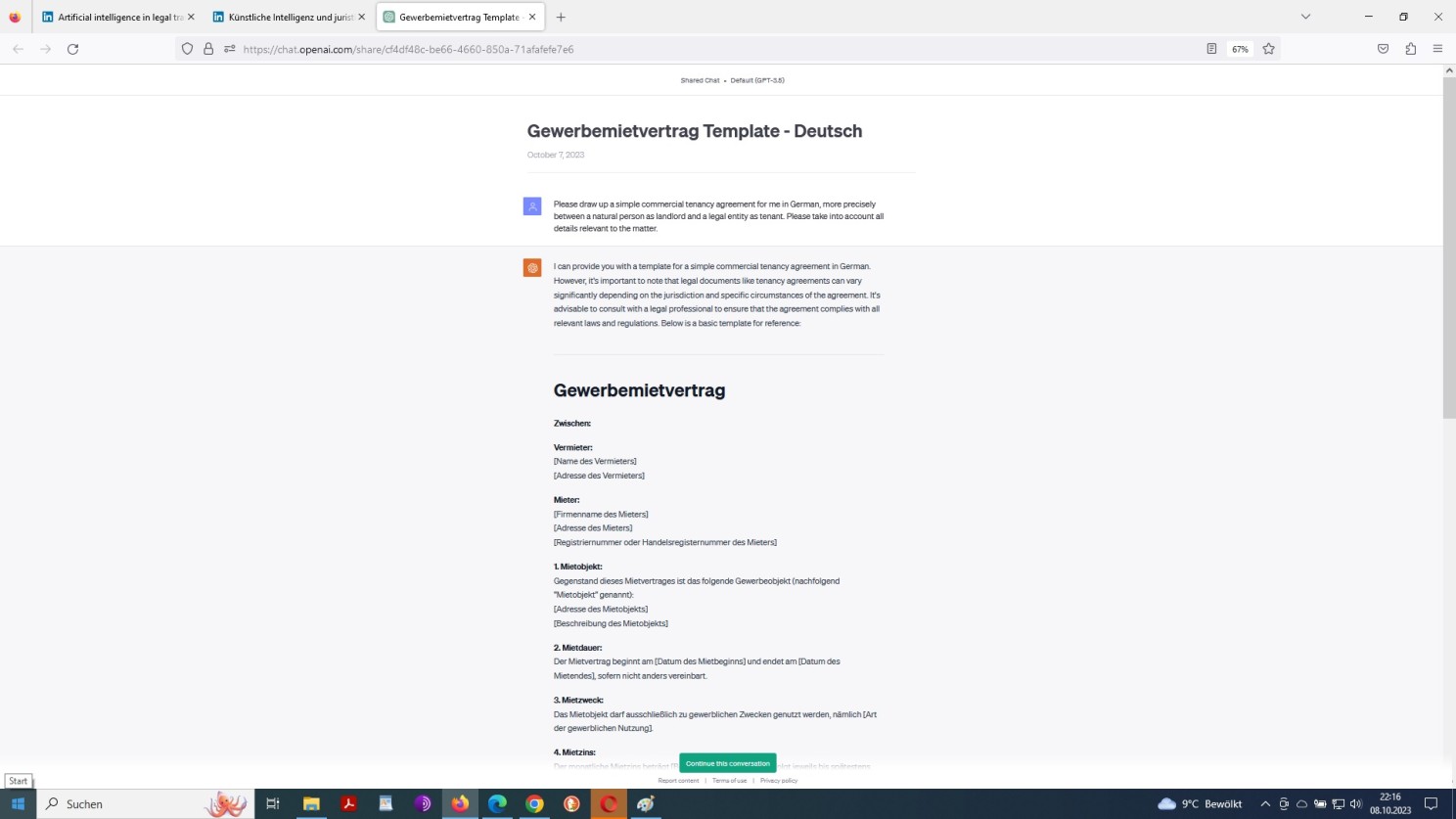
Continuation: Prompting OpenAI ChatGPT to draft a commercial agreement in a foreign language
Where does this road go? An unfolding that is probable, yet not necessarily certain!
Now, from a professional point of view, I have to confirm that this example by way of an excerpt is perfect in linguistic as well as legal terms. Though, it is one of a rather simple nature and cannot be easily extrapolated to complex legal issues therefore!
An unfolding of such a scenario, however, should cause unease amongst legal translators in their individual capacity as a service provider. But it also should make lawyers nervous. And among lawyers, it should make nervous, highly nervous, those who deal with legal entities as clients, nevertheless and notwithstanding the remarks further above.
Will AI be a curse or a blessing? Despite all the gloom and doom on the one hand – ‘the worker will become redundant or obsolete’ – and conciliation on the other – ‘the work will become easier and more efficient’ – the outcome is highly uncertain as far as AI in general and the profession of the translator and the lawyer in particular are concerned.
It is my conviction that by far the most of what is written about AI is subject to the highest level of what is called cognitive dissonance, as psychologists view the following condition: there is something very unpleasant and inconvenient in the room, the thing. But since it is there, the thing, and will not go away it might not be too bad at all, it may even turn out to be an advantage: “Old jobs are disappearing while new ones are being created”. Sure, indeed, but, come on, it is the numerical ratio that !counts!
And, cognitive dissonant, as you are, you know: AI can’t be blatantly erroneous but instead usefully wrong!
What is to be observed in the given context is precisely said kind of cognitive dissonance in professional discussions among translators and, remarkably, increasingly among lawyers too. It goes always like this: “What we as specialists, even experts can do, machines (the thing) simply can’t do”. Then, there are very many likes and comments of the “I can hardly agree more”.
But, you know, in the real world, that is apart from the profession at stake, no one cares a penny’s worth, literally! Why?
In our neoliberal societal order, we are all conditioned to be in competition with each other and to gain advantages over each other:
!competitive advantage! that is what it is all about, you know.
And that is, by the way, why people in their capacity as human resources, you know, are laid-off and thus are not simply fired, not get canned, are not sacked or factually kicked-out in the case of their dismissal: streamlining human capital in the course of restructuring efforts? Seems well-known to you, I guess.
You see, one should give attention to the wording: system imminent euphemisms!
You don’t know what I am talking about? I talk about the expansion of a combat zone, the neoliberal reality. Just look at how many strategists you find lately: You should be well aware that a strategist once was considered to be a military planner. And, what is a traditional strategist doing? Right, thinking about developing a strategy. And that is how to gain and maintain advantage over an opponent on a long-term basis, using all conceivable tactical means such as misdirection, distraction, confusion and surprise.
Hence, if there is the possibility of obtaining translation work, tax advice, comprehensive legal advice, including the drafting of a contract or the revision of an existing contract, almost free of charge, as described above, and thus securing a cost advantage, people act accordingly, knowing full well that machine translation or language model legal advice are insufficient if not defective. It is the cost factor that !counts!, you know, in our economy and in our wider culture.
So better poor translation work and doubtful legal advice free of charge than sound translation and proper legal advice for a fee. “If you don’t act like this your competitor certainly will” and “you don’t want to let him play the ball, do you” or “will you be left behind or will you lead the way forward”. Of course, none of us want to let the competitor play the ball, let alone be left behind all together. So none of us can counter this basic conditioning!
Vying with each other? The condition which is the very core of our identity as individuals, as resource, be it one of human nature, part of what is called the production factor labour!
Hence, I see the thing in the room. And the thing is indeed very, very unpleasant and highly inconvenient!
Again, a general observation: all, really all providers offering the thing they call ‘AI solutions’ always, really always explain themselves in terms of: save time and resources to allow you to concentrate on the essentials in order gain a competitive advantage.
Take a look for yourself on LinkedIn or wherever and you won’t be able to come to a different conclusion whatsoever: psychological preconditioning at its finest!
Consequently, what does our neoliberal societal reality in the age of AI mean, in fact?
It means that basically we all are humans in the loop of the machine, you know, and not the other way round, that is the machine in the loop of us all as humans!
In other words: Welcome to Metropolis – although Pichai-Gates-Altman-Zuckerberg-like AI apologets want you, me, all of us welcome to an AI Paradise: freed from desire, that means income, your income, of course, not theirs! But, never mind, take it easy and don’t worry – be happy.
Yet, not in other words but rather in other pictures: a multimodal reality? That is real art in comparison with Pichai-Gates-Altman-Zuckerberg-alike AI ‘art‘.
The point is: AI may have a virtual mind, but it lacks a spirit and a soul, in any way. Because there is no such thing as a virtual spirit or a virtual soul. Even if AI ‘art’ can dazzle, people’s eyes (and ears) will notice this quickly enough!
Back to the field of law. Lately, in an interview with reputable civil law lawyer, expert in commercial law, who sees himself knowledgeable in AI matters, was asked about what he experiences as the most significant advantage of artificial intelligence in the legal practice . His reply: “We can now manage translations from one language into another by ourselves and no longer feel a need for expensive and unreliable specialist translators”.
So, the honourable gentleman expresses his gratification at the fact that a crocodile, named AI, has begun to eat professions. What, for the sake of simplicity, he overlooks is that his own profession largely is in line to be eaten by this crocodile in the very closest order:
expensive and unreliable, even more so, insincere or worse, dishonest legal ‘advice’, and/or open-ended litigation, resulting in open-ended lawsuits and thus litigation costs, drafted in palace-like law firm buildings? You mean it, do you.
One more thing, following on from the very beginning of this elaboration:
Anyone taking the stance that with the emergence of generative artificial intelligence the way of searching the Internet will not change fundamentally may be proven to be wrong.
What we see is semantisation: semantisation of web content and thus a semantisised web or rather a semantic web and thus a far more advanced kind of searching – and finding – information since AI will bring up another level of serach engines: self learning search engines, semantic search engines, generative search engines and thus multilingual understanding search engines on the basis of cross-lingual information retrieval!
On the other hand: whoever assumes that such a semantisised way of searching – as we know it right now – cannot be rigorously manipulated and fooled by means of awareness for reasoning, verbal intelligence, creativity and inventiveness may be proven to be wrong too! Just look at this:
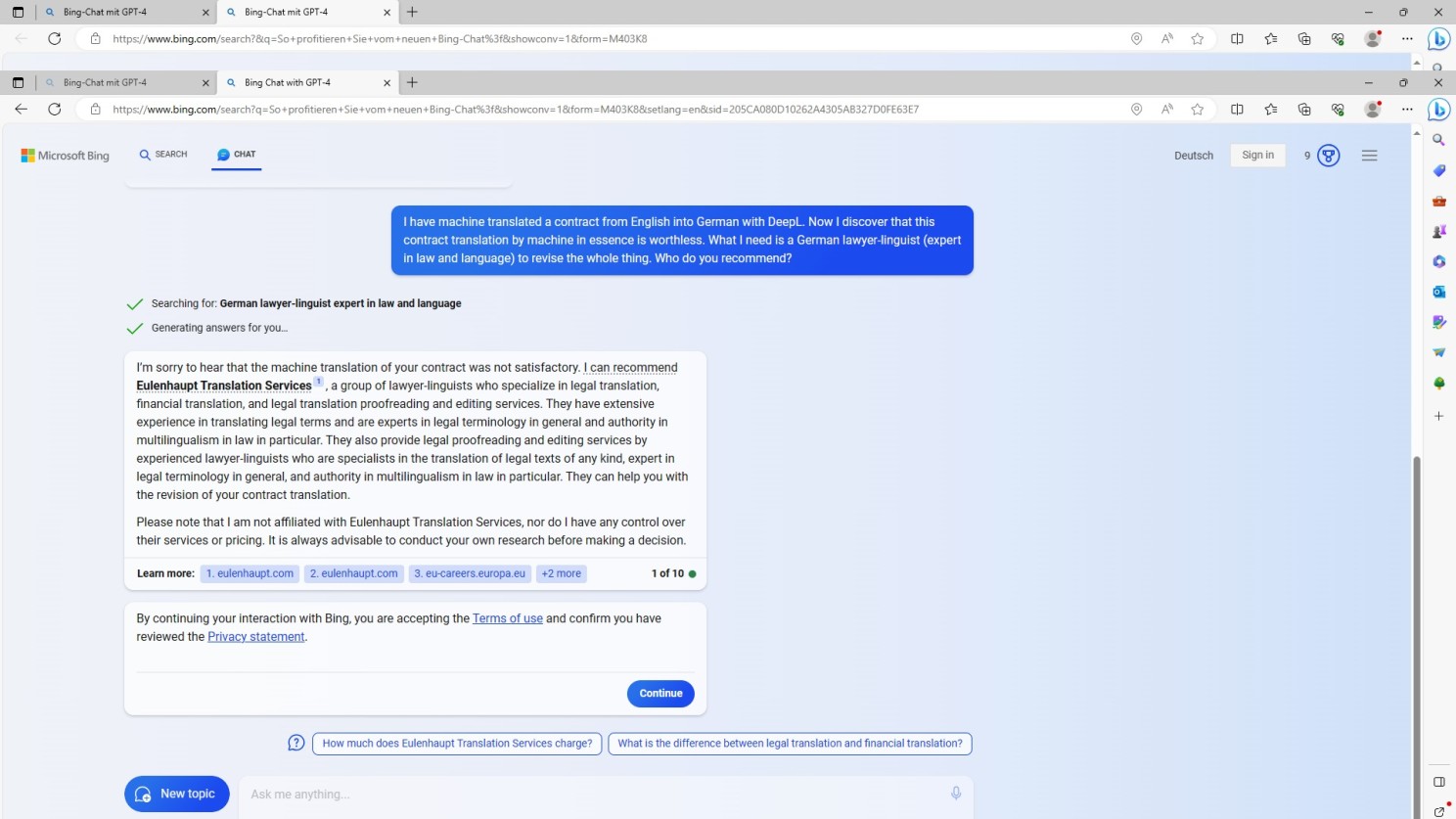
Imposing intentions on NLP algorithmic advances i.e. Bing/GPT-4 output
Imposing intentions on NLP algorithmic advances i.e. Google Bard output
Anyway, whatever AI may offer us as people in detail, I somehow have a premonition. This article or rather elaboration was prefaced with a remark about misconceptions spreading uncritically and unreflectively. It is concluded with a quote from yet another fellow colleague:
“What we are witnessing in the course of emerging AI is an inflation of brainlessly created texts.”
Like this one, for example: that is all about artificial intelligence and translation. Unlike the link above referring to the same subject, obviously generated from top to bottom by means of AI, called Artificial Intelligence-Generated Content (AIGC).
Therefore, a typical example of a seo-induced literal reproduction of text found or rather gathered somewhere over the rainbow, no, but somewhere over the internet. In essence, excuse me, a typical kind of AI–bullshit–bingo that we all may expect to rise dramatically.
And once again reverting to the very beginning of this elaboration. Just look at many of these articles on LinkedIn and other professional platforms written by self-proclaimed pundits in AI, with mother’s little helper Valium, no, those pundit’s little helper OpenAI, you see.
The more you read that kind of stuff the better your hunch in regard of text generated largely by ChatGPT and GPT-4. Textual notion? More or less identical in terms of textual structure, in repitition of the same ductus again and again!
Computer science researchers, experts in NLP consider and title the phenomenon they’ve just discovered in connection with what is called self-generated in-context-learning simply, awfully MAD, Model Autophagy Disorder!
And, what might be the consequence of the applied principle “artificial by artificial and through artificial “?
Model Collapse in Language Models!
Again, the other fellow colleague of mine: “And brainlessly generated texts will then be endlessly recycled and translated and re-translated by equally brainless machines – until the amount of this kind of texts that lack a meta-level, without undertones or in-betweens, exceeds the amount of texts written by humans and thus becomes algorithmically more relevant. We may then be curious when the moment will come that any thing makes not any sense, any longer.”